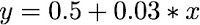A um certo tempo atrás, meu colega Pirula fez um video falando sobre testes em animais no qual ele menciona sobre a necessidade de controlar variáveis durante a realização de um estudo com o objetivo de identificar efeitos de tratamentos médicos.
Apesar da questão ética ser de grande interesse meu, não é exatamente esse o meu foco aqui. Durante o vídeo, Pirula dá alguns exemplos do que seriam “variáveis” e passa a bola para o Bernardo (do canal NerdCetico) explicar em mais detalhes. Eu assisti o vídeo do Bernardo e não acho que ele fez um bom trabalho. Meu objetivo aqui não é mostrar que o Bernardo está errado, pois não sei disso: ele tem formação matemática e eu não. Ou seja, a diferença de nossas explicações podem ser meramente um reflexo do jargão das diferentes áreas. Porém posso dizer que estou relativamente familiarizado o jargão experimental de alguns ramos do conhecimento, especificamente em biologia. Visto que o tema original era sobre experimentação em animais, imagino que minha exposição chegue mais próxima do que o Pirula tinha originalmente em mente, e complemente a explicação sobre o porque precisamos controlar variáveis de um ponto de vista estatístico prático (se é que podemos conceber algo assim).
Sendo assim, vamos aos termos:
O que são variáveis?
Variáveis são quaisquer aspectos de um sistema sob investigação que podem variar entre as diferentes observações. Em outras palavras, é o que pode variar entre diversos objetos ou fenômenos que caem dentro da mesma categoria. Por exemplo, se eu estou investigando cadeiras, variáveis possíveis são desde o peso, o material do qual ela é feita e até mesmo se o seu design se enquadra no movimento bahaus ou não. Ou seja, não existe uma regra que determina que uma variável necessariamente é expressa em valores numéricos, como normalmente se pensa.
Em sistemas biológicos temos uma multitude de características que variam entre os diversos organismos: cor, tamanho, forma, número de células, capacidade de manutenção de temperatura, grau de atividade, idade, etc. Dentro dessa pluralidade de variáveis podemos reconhecer alguns tipos gerais:
-Variáveis Qualitativas, Categóricas ou Discretas: são todas aquelas que podem ser expressas em categorias que agrupam todos os objetos que possuem aquela característica específica. Por exemplo, quando tentamos identificar a espécie em roedores silvestres, a pelagem é uma característica bastante importante, podendo variar em cor e em tonalidade. Normalmente tais variáveis não apresentam o que chamamos de “ordenação”, ou seja, não existem valores intermediários entre as categorias: um organismo pode ser autotrofo ou heterótrofo, sendo que não existem intermediários entre essas categorias.
–Variáveis Quantitativas ou Contínuas: são todas aquelas que variam ao longo de um escala contínua. A grande maioria das grandezas físicas varia dessa forma: peso, massa, aceleração, etc. Muitas variáveis biológicas também se comportam desta forma, como taxas metabólicas, comprimentos de estruturas biológicas, período de atividade, força de mordida, porcentagem de matéria vegetal na dieta, etc.
–Variáveis Ordinais (ou semi-quantitativas): assim como as variáveis categóricas, são compostas por classes mutuamente exclusivas. Assim como as variáveis contínuas, essas categorias estão ordenadas de alguma forma, ou seja, existem valores mais baixos, intermediários e maiores. Exemplos desse tipo de variáveis são contagens de eventos, ou qualquer outro tipo de variável expressa por números inteiros (e.x: 1, 2, 3, 4…).
Nem sempre um tipo de fenômeno precisa ser avaliado necessariamente como um tipo único de variável. Por exemplo, podemos avaliar a altura dos indivíduos de uma população de como uma variável quantitativa (medida em centímetros) ou de forma qualitativa (indivíduos “altos” e “baixos”) ou ordinal (indivíduos “pequenos”, “médios” e “grandes”). Tudo depende do tipo de investigação que está sendo feito, nossa capacidade de medir os fenômenos, etc.
Relações entre variáveis
Uma metodologia comum em investigações científicas é o estudo das relação entre diferentes variáveis, com o objetivo de testar previsões teóricas (ex: tal remédio é seguro para o uso). Nesse contexto, costumamos interpretar o valor de uma variável como uma função dos valores de outra variável. Por exemplo, no exemplo abaixo, y é uma função dos valores de x:

Neste exemplo, a relação entre as variáveis é linear, ou seja podemos entender que a relação entre elas é dada por uma reta (ou por uma equação de primeiro grau), na qual cada valor de x tem um valor associado de y. O que é interessante notar é que nessa caso temos uma variável y que depende do valor de x de forma linear (ou seja, segundo uma equação de primeiro grau do tipo). Por esse motivo chamamos y comumente de variável dependente e o x de variável independente.
Quando analisamos estatisticamente duas variáveis, digamos, dosagem de uma droga experimental e taxa de recuperação, o que fazemos é tentar achar as relações de dependências entre elas. Ou seja, no exemplo, precisamos achar como a taxa de recuperação (Tr) depende da dosagem (d) da droga experimental. Estatisticamente a relação entre essas duas variáveis é dada pela função

onde a0 e a1 são coeficientes da função linear e epslon (simbolo que parece um “e” no fim da equação) é o que chamamos de “erro“, que contem tudo aquilo que não estamos interessados no momento, como peso do indivíduo, idade, dieta, etc. Dessa forma, os métodos estatísticos nos permitem avaliar o que é o real sinal nos nossos dados (ou seja, qual é o efeito da droga na recuperação) do que não nos interessa naquele momento.
Porque controlar o erro?
Visto que o erro em uma analise pode ser controlado estatisticamente, então porque devemos controlar esse erro, ou melhor, no contexto da discussão inicial, porque devemos usar animais de laboratório, que são todos homogeneizados para minimizar tais erro?
O motivo é basicamente estatístico. Quando nosso erro não está controlado, ele pode apresentar uma magnitude grande demais, o que dificulta a identificação da real relação entre as variáveis. No exemplo abaixo, a relação entre as variáveis é a mesma (y=0.5+0.03*x), mas o erro na segunda analise é muito maior do que na primeira. Note também que as retas são bastante diferentes, indicando que a reta obtida com maior erro é muito diferente da real.

Outro ponto é que para o erro (pequeno ou grande) ser considerado como tal em analises estatísticas, ele tem que ser aleatório, ou seja, não pode mostrar forte associação ou padronização com qualquer outra variável que possa ser relevante para o nosso estudo. Quando isso ocorre, tais variávies precisam ser incorporadas explicitamente na analise, onde cada variável que existe na população deve ser avaliada:

Onde todas as variáveis são expressas por x e seus coeficientes lineares por a. Nesse exemplo, a taxa de recuperação é uma função não apenas da dosagem do remédio, mas da idade, peso, dieta, tipo sanguíneo, sexo, etc.
Entretanto, a solução não é simplesmente coletar mais informações sobre os indivíduos que estão na análise. Existe um numero mínimo de indivíduos que precisam ser utilizados que aumenta a medida que avaliamos mais e mais variáveis. Esse número mínimo é uma função de diversos fatores, e existe toda uma área dedicada ao estudo desse tipo de coisa, porém uma coisa pode ser colocada categoricamente: o número de indivíduos na sua análise nunca pode ser inferior ao número de variáveis abordadas explicitamente. Ou seja, se formos em uma população humana natural, quantas variáveis devem variar de forma significativa? Cinqüenta? Trezentas? Acho que dá para pegar a idéia. Adicionalmente, quando avaliamos um número muito grande de correlações, existem sempre a possibilidade de identificar correlações onde na verdade não existem nenhuma, por puro acaso (é o que os estatísticos chamam de erro do tipo I).
Isso talvez ajude a entender porque muitas das análises sobre benefícios de algum tipo de alimentação variam tanto. Via de regra, tais estudos tem que ser realizados na população humana, incluindo todos os problemas metodológicos colocados. Ou seja, o resultado pode variar tanto não porque os “cientistas não se decidem se ovo é bom”, mas porque os indivíduos amostrais para esse tipo de investigação (e.g. seres humanos sem controle algum) são particularmente ruins para análises estatísticas.
Em outras palavras, testar um produto em uma população não controlada não é apenas perigoso (afinal, estamos falando de medicamentos, e não shampos para cabelos secos), mas é ciência ruim.