Computational Thinking and Gender
A few weeks ago I was challenged by Professor Mauricio Rosa, from the Faculty of Education at the Federal University of Rio Grande do Sul, to see Mathematics as a channel for non-exclusion (yes, it was a rather atypical but enriching lecture).
One aspect I learned and is worth sharing is that non-exclusion is not synonymous with inclusion. Since inclusion is only necessary in environments that exclude, while the idea of non-exclusion is that the environment does not exclude, therefore, there is no need for an inclusion movement.
We can think of the online chess game environment as a place of non-exclusion. We know next to nothing who we are playing against, at most the nickname, the informed nationality and the participant’s win rate. In this environment perhaps the main exclusion factor is the ability to play chess, but even this seems to occur in a subtle way, as the games are usually allocated against opponents with close win rates. Even so, there are inclusion factors regarding the ability to play chess, as it is possible to confer some advantages on players with a lower winning rate in order to balance the challenge of the game for both.
Anyway, responding to the challenge of Professor Mauricio Rosa, I decided to write this post about Computational Thinking and gender.
When we study Computational Thinking in Jeannette Wing’s view, we understand that it refers to the way Computer Scientists seek to solve their problems by having computational resources at their disposal. It involves understanding that there are actions that the human being performs better than the computer, but also actions that the computer performs better than the human being. Just think of the difficulty for a computer to maintain a coherent dialogue in a simple chat bot, compared to the difficulty for a human being to operate a spreadsheet with thousands of cells. Thus, the combination of human capabilities with the proper use of computational resources would be the best way to solve a wide range of problems.
We have to keep in mind that managing how much of the task will be assigned to human beings and how much will be assigned to computers, is Thinking Computationally. So, let’s go to an application that a few months ago was viral on the internet, FaceApp.
It’s a cool application for thinking about haircuts, if we dye our hair, if we grow a beard, it allows us to easily and with reasonable quality, to alter photos to preview some changes. But of course, the app isn’t perfect and shouldn’t be. I say that in some photos you can even detect the presence of a person, or in others, along with your hair, tear off part of your head. Anyway, some setbacks that wouldn’t be worth in terms of software complexity, fix them, since most of the time it generates a satisfactory result.
However, within this idea of satisfactory result, there is an application characteristic. Once a photo is uploaded, the software tries to decide based on the characteristics of the image, whether the functionality palette will initially be male or female. A function that perhaps most users use without even thinking about what this decision was based on. After all, we weren’t given an option to tag with our human abilities which tool profile we feel is appropriate for editing this image.
Probably during the development phase, they figured that this lack of choice would be less harmful than the excess of options. That is, more users would rather have the software make this decision automatically every time, than have one more button to press before they start editing the photo. It’s natural for us to think that way, Gmail itself notifies us without asking, if it has the expression “follows in attachment” in the body of the email, and does not have any attachment inserted.

Anyway, maybe most people who write an email saying “attached” but who haven’t attached any file really want to attach a file but have forgotten. Therefore, the small portion of the population that sends emails saying “attached” without actually wanting to attach anything, will need to have the email sent consulted by this dialog box. The computer in this case is making what seemed to be the best decision for most users.
Then we come to the issue of gender, going back to the FaceApp software, it initially presents the tool interface with a male or female profile automatically. Based on very subtle aspects of the photo. But so subtle that I challenge whoever is reading it to see the two photos of me below and answer, in which the software decided to display the female profile for the left photo and the male profile for the right?
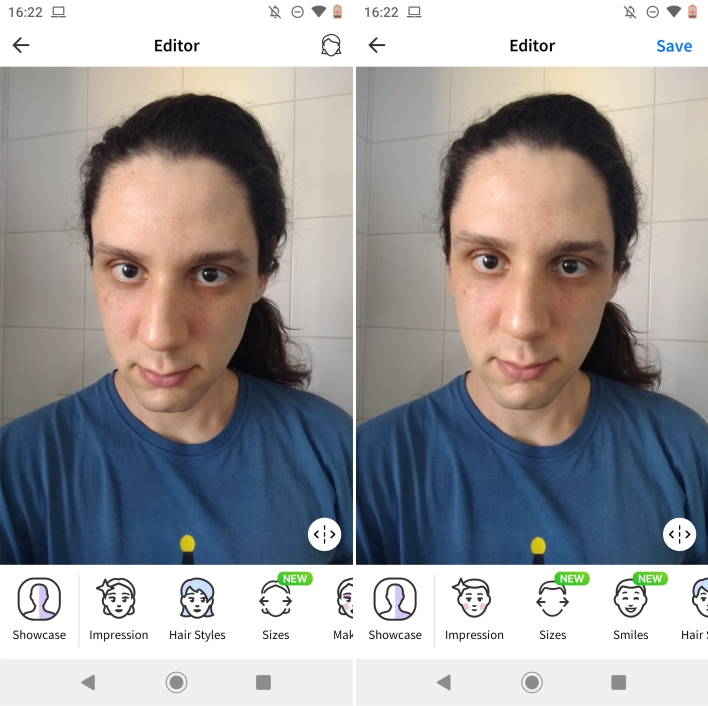
In this case, we need to understand how the software knows how to assess people. Most likely in this case, he uses an artificial intelligence technique of Machine Learning. Thus, the software initially developed would take a large number of image characteristics and try to identify what would be the nose, eyes, mouth… from these references to what would be a face, it takes the other observable measurements, but does not make any assessment yet.
To assess whether to assign the status of the photo to female or male, the software needs to understand the meaning of these two words. But these are already complex words even for human beings to be able to explain with clarity and objectivity, who would say explain them to software. The idea in this most likely case is that the software has been calibrated from a large database with photos of people already labeled as female or male. In this process, the software tries to learn how to relate these observed measurements of the face to the photo labels. So, at the end of this training, the software satisfactorily knows how to use the observed measurements of people’s faces to determine whether to attribute the female or male label to them.
But keep in mind that the software doesn’t know what these two labels are, it just understands that after a certain value it must assign a specific label. This process of verifying the measurements and giving the labels, the computer does in an excellent and impeccable way! The problem however is with the photos that were not part of the initial database.
The software in this case, is building on what it learned during its training, and looking for the best way to get the labels right as it was programmed to do. But what separates one measure from another? How to assess measures close to the divide between labels? If we separate people by tall and short, it would be correct to say that someone who is 1.50m tall is short while another person who is 2.00m tall is tall. But what about intermediate values? 1.69 m is low? 1.70 is high? What is the fine line that separates these two labels? There is no point in saying that 1 cm separates a tall person from a short person. Ideally, we would create intermediate categories. Thus, with the increase in height categories, it makes more sense to say that a few centimeters separate one category from another, even though we have the same problem if we reduce the difference to 1 mm.
With this, we can see that even for height, which seems to be a clear measure of the human being, it is subjective to create labels.
In the case of the software, it separates people into female and male based on measurements, and you need to make this decision even when the differences between categories are minimal, as in my two photos shown above.
Anyway, the reason the software has two categories comes from a set of tools to edit the image having been initially calibrated to only two categories.
Well, now that we understand a little of how the FaceApp application works when we upload a new photo, we can see that the “automatic choice” between female and male is an element of exclusion of minorities. Because just like in Gmail, they don’t expect users to send emails saying “attached” but intentionally without an attachment, in this app they expect users to most of the time feel represented by this automatic choice.
An issue that could be minimized with an initial option for the user to choose between the female or male option right after uploading a photo. But this still would not solve the problem of exclusion of minorities, as it restricts the person to choose one of the two options, ignoring the others. In this sense, we can think that the restriction of options is due to the better adjustment of the photos, within the modifications that the software makes based on that huge database used to learn how to work with human faces.
To conclude, see that the deletion provided by the software can be minimized by simply asking what option the user wants for that photo. A situation that is very similar to our daily lives as human beings, that when we meet a new person, we usually save the question “would you prefer me to refer to you with what pronoun?”.
Although simple, this prevents us from carrying out an evaluation process based on visual aspects to determine which label we will give to the person, while also not excluding who we refer to since we are not as restricted as software tools .
I hope you enjoyed this post 🙂 and that reflection can somehow favor the use of Mathematics as a channel for non-exclusion.
Cover image credits to Gerd Altmann from Pixabay