Pesquisador, carreira Pq-A do NICS / UNICAMP. Professor pleno da Coordenadoria de Pós-graduação do Instituto de Artes da UNICAMP. Pós-doc em Cognição Musical na Universidade Jyvaskyla, Finlândia. Visitante escolar no CCRMA / Stanford University. Doutorado e Mestrado na FEEC / UNICAMP. Formado em Música popular (piano) e Engenharia elétrica na UNICAMP.
Na semana passada iniciei uma descrição do caminho trilhado pelo desenvolvimento científico e consequentemente tecnológico da computação musical. Continuo agora a partir do lançamento do primeiro sintetizador digital musical, no começo da década de 1980.
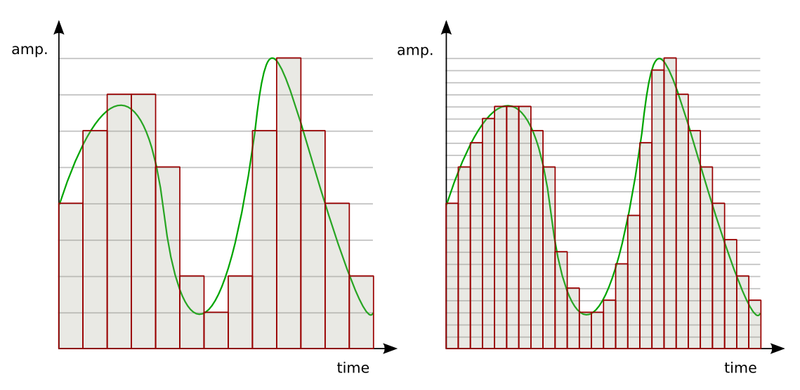
Sinal (som) contínuo (analógico) e discreto (digital). Fonte: https://commons.wikimedia.org/wiki/File:SSampling.png
Este período foi também marcado pelo início da exploração e implementação em larga escala da eletrônica digital que apresenta diversas vantagens tecnológicas sobre a eletrônica analógica, em especial com relação a sua simplificação de modelamento matemático e a consequente facilidade de ser implementada computacionalmente. Apesar do primeiro teclado musical que se tem registro ter sido construído no século 19 DC, pelo inventor Elish Gray (intitulado, “The musical telegraph“), o primeiro teclado eletrônico foi comercialmente disponibilizado na década de 1950, por Wurlitzer, baseado num teclado anterior desenvolvido por Fender Rhodes. Na década de 1960 e 1970, houve a grande explosão de criadores de teclados eletrônicos, como os famosos Moog, desenvolvidos por Bob Moog, que criou uma série de teclados sintetizadores analógicos, ou seja, que utilizavam processos eletrônicos contínuos (analógicos) pra gerar o áudio em “tempo real” (no momento em que eram “tocados”). Em contraste, a síntese digital é baseada em processos matemáticos discretos (não contínuos) para gerara o áudio (no caso, digital) em tempo real.
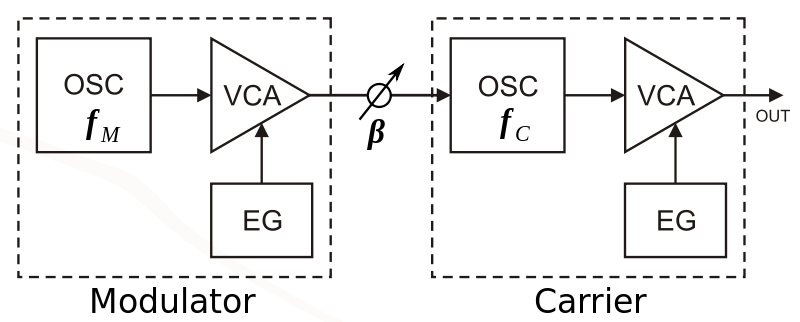
Exemplo de síntese FM com 2 osciladores (OSC) com controle dinâmico de amplitude (VCA controlado pelo gerador de envoltória EG). Fonte: https://commons.wikimedia.org/wiki/File:2op_FM.svg
A síntese FM foi, desde o seu início, desenvolvida como um processo digital de síntese sonora, o que tornou o DX7 o primeiro sintetizador digital comercialmente disponibilizado. Do mesmo modo, em paralelo, outros pesquisadores exploravam diferentes possibilidades de sínteses sonoras digitais. Já se sabia da possibilidade de simplesmente somar oscilares senoidais para simular, em teoria, o timbre de qualquer som conhecido, como aqueles gerados pelos instrumentos musicais. Isto é uma consequência direta da teoria de Fourier (mencionada anteriormente) que prova matematicamente que qualquer som periódico pode ser representado por uma soma finita de senoides com diferentes amplitudes, frequências e fases. Assim, diz-se que o som é constituído por parciais (senoides) e cada parcial pode ser representado por um oscilador senoidal.
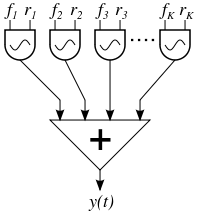
Exemplo de síntese aditiva, baseada na soma de osciladores, cada um representando um parcial do som. Fonte: https://commons.wikimedia.org/wiki/File:Additive_synthesis.svg
O problema na época era a constrição computacional de gerar e controlar uma grande quantidade de senoides. Dados os parcos recursos de processamento e memória computacional até a década de 1980, era computacionalmente muito caro criar em escala comercial um hardware capaz de calcular e controlar os parâmetros de um grande número de senoides em tempo real, ou seja, com atraso imperceptível para sintetizar um som desejado durante a performance, como fazia o DX7, que era capaz de processar até 16 notas simultâneas de sons com timbre bastante complexos. No entanto, como é comum na natureza, a síntese FM também tem a sua contrapartida. Esta é um processo não-linear de geração sonora, o que significa dizer que esta não permite um design intuitivo do timbre sonoro que se quer criar, como seria o caso de uma síntese linear, como aquela baseada na teoria de Fourier, que criasse um timbre pela adição de osciladores, conhecida como “síntese aditiva”. Por outro lado, um som complexo pode ter uma imensa quantidade de parciais (componentes senoidais que constituem o som), o que acarreta na necessidade de se utilizar uma imensa quantidade de osciladores pra sintetizar todos os parciais necessários pra constituir um som desejado, através de um método linear de síntese. Assim, tem-se um compromisso entre sínteses lineares (que apresentam um design sonoro intuitivo mas requerem muitos recursos computacionais para serem calculadas) e as sínteses não-lineares (que requerem bem menos recursos computacionais pra processar um som, porém não apresentam um design sonoro intuitivo).
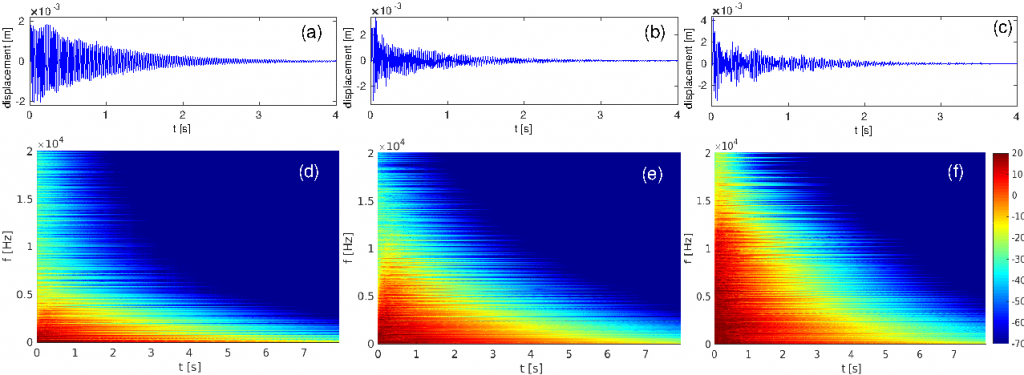
Exemplo de espectrogramas de diferentes sons percussivos, denotando a riqueza harmônica (a quantidade de parciais) deste som. Fonte: http://perso.ensta-paristech.fr/~touze/tapercymbals.html
Com o passar do tempo, a síntese FM começou a soar repetitiva, uma vez que o processo de design sonoro tendia a ser repetida com pequenas modificações. Desse modo, novas formas de síntese sonora, que produzissem sons ainda mais similares com os gerados por instrumentos musicais, voltaram a ter procura, aumentando assim a oferta de novas tecnologias sonoras.
Exemplo simples de um algoritmo de síntese Karplus Strong. Fonte: https://commons.wikimedia.org/wiki/File:Karplus-strong-schematic.svg
No começo da década de 1980, Alexander Strong e Kevin Karplus desenvolveram um método de síntese sonora baseado na simulação das propriedades físicas de uma corda retesada que gera som ao ser excitada (pinçada ou percutida). O modelo, conhecido posteriormente apenas por “síntese Karplus-Strong”, era muito simples e gerava sons muito similares ao som gerado por um instrumento musical de corda. Isto abriu a possibilidade de uma nova forma de síntese sonora, que simula computacionalmente as propriedades físicas que geram o som de um instrumento musical (por exemplo, no caso de um violão, a oscilação das cordas, com suas forças de retesamento, proporções, densidades, etc. , o corpo do instrumento, com suas geometrias, dimensões, características físicas do material utilizado, etc.). Julius Smith, um pesquisador do CCRMA, baseou-se no modelo de Karplus-Strong para criar o modelo de síntese batizado por ele como “Digital Waveguide Synthesis”. O termo “waveguide” ou “guia de ondas” refere-se a métodos utilizado na física para o estudo e dimensionamento de estruturas físicas que permitem a propagação de ondas acústicas ou eletromagnéticas, com um mínimo de perda. Do mesmo modo que Chowning (pai da FM) havia feito 2 décadas antes, se inspirando na modulação FM de ondas de rádio para criação de um processo de síntese sonora, Smith se inspirou no modelo de Karplus-Strong expandindo-o através da utilização do modelo matemático das guias de onda, para criar um novo modelo de síntese sonora: uma síntese sonora por modelamento físico do instrumento musical. Esta foi posteriormente patenteada pela universidade Stanford e também licenciada para a Yamaha, em 1989, onde foi expandida para representar diversos outros instrumentos musicais. Esta passou a ser conhecida como “Physical modelling synthesis”. Em 1993, um ano antes do primeiro SBCM, (em Caxambu, MG, 1994) a Yamaha lançou o primeiro sintetizador digital com o modelamento físico, o VL1. Apesar da eficiência do algoritmo das guias de onda, dadas as restrições tecnológicas da época, o VL1 permitia processar apenas uma nota por vez (ou seja, diferente do DX7 que, lançado uma década antes, tinha uma polifonia de 16 notas simultâneas, o VL1 permitia tocar apenas 1 nota por vez, ou seja, era um instrumento musical digital monofônico). Quando estive no CCRMA, no final da década de 1990, cheguei a experimentar um desses teclados. O que me impressionou do VLS1 foi a riqueza timbrística do som monofônico gerado, e especialmente a controlabilidade que sua sonoridade apresentava (era possível, por exemplo, controlar em tempo real detalhes sutis do som, como: ligaduras, abafamentos, surdinas, palhetadas, harmônicos, glissandos, tracejados, etc ). No entanto, comercialmente o instrumento era muito caro, além de monofônico. Apesar do modelamento físico ser de fato um conceito muito interessante, este demonstrou ser pouco eficiente para a geração de timbres de diferente instrumentos, como já havia sido insinuado pela síntese Karplus-Strong, que servia bem aos propósitos de simular cordas, porém nada mais do que cordas.
Nos próximos artigos irei continuar discorrendo sobre os caminhos dos avanços da computação musical, até chegar aos dias de hoje.
Referências:
[] Archives of Brazilian Symposium on Computer Music (SBCM) http://compmus.ime.usp.br/sbcm/
[] SBCM 2019 http://compmus.ime.usp.br/sbcm/2019/
[] Karplus, Kevin; Strong, Alex (1983). “Digital Synthesis of Plucked String and Drum Timbres”. Computer Music Journal. MIT Press. 7 (2): 43–55. doi:10.2307/3680062. JSTOR 3680062.
[] Julius O. Smith (2008). “Digital Waveguide Architectures for Virtual Musical Instruments”. In David Havelock; Sonoko Kuwano; Michael Vorländer (eds.). Handbook of Signal Processing in Acoustics. Springer. pp. 399–417. ISBN 978-0-387-77698-9.
[] McNabb, Michael. “Dreamsong: The Composition” (PDF). Computer Music Journal. 5 (4). Retrieved February 24, 2015. http://www.mcnabb.com/music/pubs/CMJ_Vol5Num4.pdf
[] The History of the Electric Keyboard. By Gary Hill ; Updated September 15, 2017. https://ourpastimes.com/the-history-of-the-electric-keyboard-12310595.html
[] Sound synthesis of cymbals including thickness and shape variations. http://perso.ensta-paristech.fr/~touze/tapercymbals.html
Como citar este artigo:
José Fornari. “Avanços e caminhos da computação musical – parte 2”. Blogs de Ciência da Universidade Estadual de Campinas. ISSN 2526-6187. Data da publicação: 17 de outubro de 2019. Link: https://www.blogs.unicamp.br/musicologia/2019/10/17/34/(opens in a new tab)
Pesquisador, carreira Pq-A do NICS / UNICAMP. Professor pleno da Coordenadoria de Pós-graduação do Instituto de Artes da UNICAMP. Pós-doc em Cognição Musical na Universidade Jyvaskyla, Finlândia. Visitante escolar no CCRMA / Stanford University. Doutorado e Mestrado na FEEC / UNICAMP. Formado em Música popular (piano) e Engenharia elétrica na UNICAMP.