ESPECIAL
Parte 3:
José Fornari (Tuti) – 20 de novembro de 2019
fornari @ unicamp . br
No artigo anterior descrevi brevemente os modelos clássicos de síntese sonora da segunda metade do século 20 DC. Do modo como entendo, os processos de síntese sonora apresentam 3 elementos principais, que eu chamo aqui de: 1) Sonoridade (a facilidade de gerar audio com grande riqueza timbrística), 2) Controlabilidade (a facilidade de parametrização das variáveis do algoritmo da síntese sonora de modo a permitir gerar com facilidade uma dada sonoridade intensionada a priori), 3) Computabilidade (a facilidade computacional, em termos de processamento e memória, para realizar a síntese sonora).
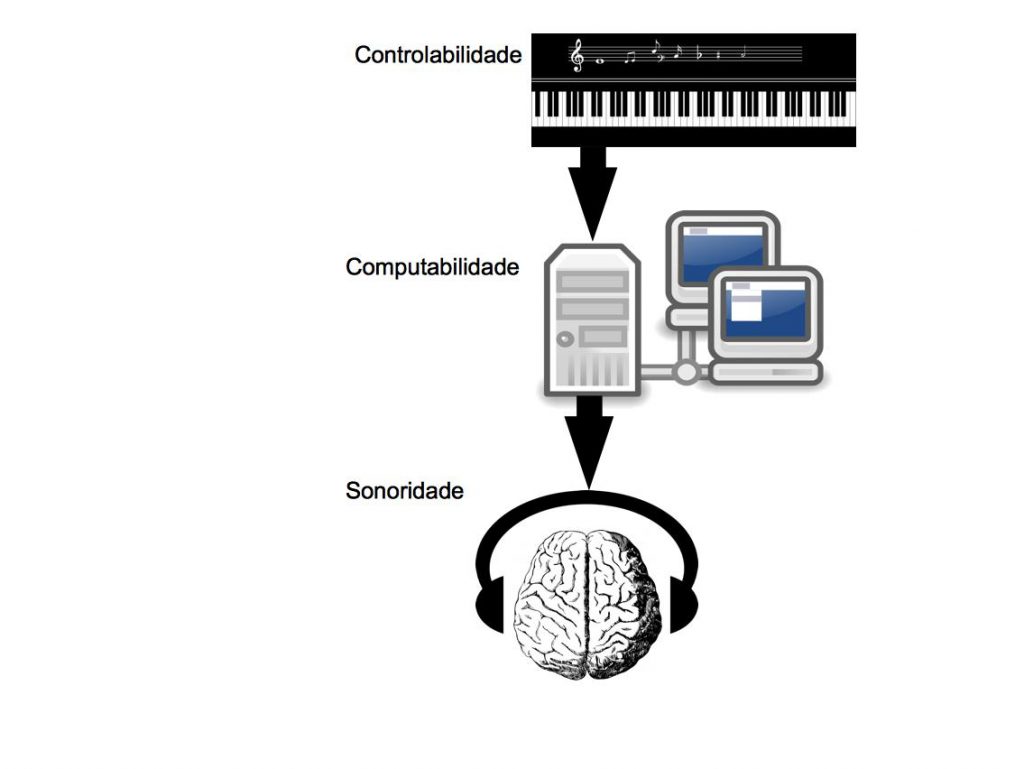
Os 3 elementos dos processos de síntese sonora digital: 1) Controlabilidade, 2) Computabilidade e 3) Sonoridade.
A síntese aditiva (dada pela construção de um som complexo através da soma de senoides dinamicamente parametrizadas) possui tanto a controlabilidade quanto a sonoridade diretamente proporcionais à sua computabilidade (o que na época anterior à síntese FM, era um gargalo em termos computacionais e, hoje em dia, é um gargalo em termos de complexidade cognitiva de parametrização). A síntese FM (Frequency Modulation, ou modulação de frequência) possui alta sonoridade e baixa computabilidade, porém sua controlabilidade não é intuitiva (dado pelo fato deste processo computacional não ser linear, o que dificulta o design sonoro com um fim estético específico). A síntese PM (Physical Modeling, ou modelamento físico) apresenta grande sonoridade e controlabilidade (já que o algoritmo parte de modelamento computacional do corpo físico de um instrumento musical) mas pouca computabilidade (já que estes modelos físicos aumentam em complexidade na medida em que mais detalhes do modelamento do instrumento musical original são adicionados).
Temos assim que, em teoria, a síntese aditiva permite gerar qualquer sonoridade intencionada, do mesmo modo que poderíamos em teoria gerar qualquer trecho sonoro ou musical (de um discurso à uma sinfonia, de um efeito sonoro à um som da natureza) com 1 minuto de duração, se ordenássemos corretamente uma sequência de cerca de 2,6 milhões (44100 x 60) de números inteiros, escolhendo adequadamente seus valores, entre −32,768 a +32,767 (equivalente aos 16 bits de resolução do padrão de áudio digital do CD). Porém, apesar desta possibilidade técnica existir (desde os anos 1980), não temos a capacidade cognitiva, ou mesmo recurso de ML (Machine Learning, ou aprendizado de máquina) capaz de realizar esta tarefa. Do mesmo modo, a síntese aditiva aumenta em complexidade a cada parcial (representado por uma senoide) acrescentada, a qual deve ser controlada dinamicamente em 3 parâmetros: amplitude, frequência e fase. A síntese FM valeu-se da capacidade criativa de designers de som que foram intuitivamente criando bancos de dados sonoros e catalogando suas sonoridades. Porém esta capacidade chegou a um certo limite cognitivo, onde novas ou mais aperfeiçoadas sonoridade musicais passaram a ser cada vez mais escassas até praticamente não mais ocorrerem. Chegou-se assim a outra constatação fundamental no universo do som musical. Os ouvintes, em sua imensa maioria, não estão interessados em novas e desconhecidas sonoridades de áudio digital, mas sim em obter através de recursos computacionais sonoridades cada vez mais parecidas com aquelas de instrumentos acústicos conhecidos, como por exemplo, o som de célebres instrumentos musicais. Deste modo, por exemplo, um teclado musical digital poderia gerar uma sonoridade similar com aquela de um piano de uma famosa e tradicional marca (como um Steinway & Sons, ou um Bosendorfer Imperial) cuja aquisição e portabilidade seriam proibitivos para a imensa maioria dos tecladistas. Neste sentido, foi desenvolvida e explorada a síntese PM, porém esta, apesar de apresentar muita controlabilidade, tem sonoridade limitada e, dados os recursos tecnológicos da época, era computacionalmente muito cara.
A ideia de gravar o som original de um instrumento musical acústico e controla-lo através de uma interface computacional já tinha sido pensada na década de 1960. No começo dos anos 1970 já existiam implementações realizadas. O primeiro destes instrumentos, chamados de “Samplers” (amostradores) foi o Mellotron, um teclado musical analógico, que gravava em tape (fita magnética) o som de um instrumento musical, o qual era depois acionado através de um teclado eletrônico. O primeiro sampler digital foi o EMS (Electronic Music Studio) que utilizava 2 processadores computacionais para realizar as operações necessárias para o “sampleamento” (conversão analógico digital, edição e armazenamento das amostras digitais). Os samplers eram instrumentos muito caros e ainda por cima necessitavam que o usuário tivesse um bom entendimento computacional e de áudio digital, para que pudesse realizar adequadamente o design sonoro do áudio que seria utilizado musicalmente, numa performance ou numa gravação musical.
A saída encontrada por pesquisadores tais como Michael McNabb e Wolfgang Palm, foi ir ao encontro do interesse da imensa maioria dos usuários, que não procuravam novas sonoridades, mas desejavam instrumentos digitais capazes de reproduzir sonoridades conhecidas e estabelecidas no imaginário sonoro dos músicos e ouvintes. Com isso, poderia-se reduzir o custo do equipamento computacional, retirando a parte necessária para converter e armazenar novas amostras e assim também eliminar o processo de edição que estava a cargo dos usuários. A solução foi criar instrumentos musicais digitais mais baratoa, já contendo uma lista pré-definida de sonoridades pré-amostradas e adequadamente editadas, de sons conhecidos (especialmente sons de instrumentos musicais acústicos). Isto foi alcançado através da utilização de tabelas de leitura na memória digital do computador (ou instrumento digital); as chamadas Table-lookup. Estas tabelas poderiam serlidas e moduladas pelo algoritmo da síntese, ao invés de calculadas em tempo real. Por exemplo, para gerar uma senoide, ao invés do processador digital calcular, a cada instante de tempo, o valor de uma função seno, tem-se uma tabela com estes valores já pré-calculados, os quais são apenas lidos em diferentes velocidades, de acordo com a frequência da senoide que se quer reproduzir, e multiplicados por uma variável, de acordo com a amplitude desejada na sua reprodução. Tem-se então a possibilidade de fazer o mesmo com formas de onda mais complexas, como são as amostras digitais de sons de instrumentos musicais, que também podem ser armazenadas numa tabela de “ondas”, chamada de “Wavetable”. Deste processo de desenvolvimento, feito por diversos e independentes pesquisadores, surgiu o conceito de “Wavetable synthesis”; a síntese wavetable.
Em linhas gerais, os sons de instrumentos musicais são compostos por dois tipos de sons, como também ocorre na fala humana, que é composta por consoantes e vogais. Conforme tratado anteriormente, as vogais são sons tonais, aproximadamente periódicos, enquanto que as consoantes são sons percussivos, aperiódicos. Uma sílaba é normalmente composta por uma vogal (quase periódica) precedida por uma consoante (aperiódica). Do mesmo modo, o som de um instrumento tonal costuma possuir uma fase inicial, chamada de ataque, que a esta se assemelha e cumpre a função identificatória de uma consoante na sílaba. Este é precedido por uma fase posterior, chamada de ciclo, que assemelha e cumpre a função qualitativa de uma vogal. A diferença, por exemplo, entre as sílabas “ba” e “pa” é de fato sutil, estando contida praticamente nos primeiros milisegundos do som de ambas as sílabas, os quais a audição humana é extremamente eficaz em distinguir.

Espectro sonoro (componentes em frequência ao longo do tempo) do áudio de uma pronuncia da sílaba “ba” onde se observa à esquerda o momento da pronuncia da consoante “b” seguido pela pronuncia da vogal “a“, que é aparte tonal deste áudio.
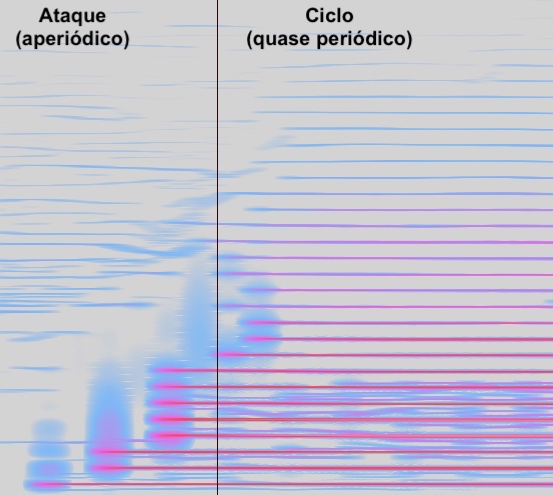
Espectro sonoro (componentes em frequência ao longo do tempo) do áudio de uma nota emitida por um trompete (coletado no site www.freesound.org) onde tem-se à esquerda o ataque (parte ruidosa ou aperiódica, similar à sonoridade de uma consoante) precedido pelo ciclo (parte tonal, similar à sonoridade de uma vogal).
Considerando essas duas partes fundamentais de um som tonal, a estratégia da síntese wavetable, de modo bastante simplificado, é amostrar estes dois componentes do som musical tonal. O ataque é de rápida duração (milissegundos) e é assim armazenado integralmente. O ciclo é bem mais extenso (depende da duração da nota) porém é “quase periódico”, ou seja, se repete de modo similar (por isso, o nome “ciclo”).
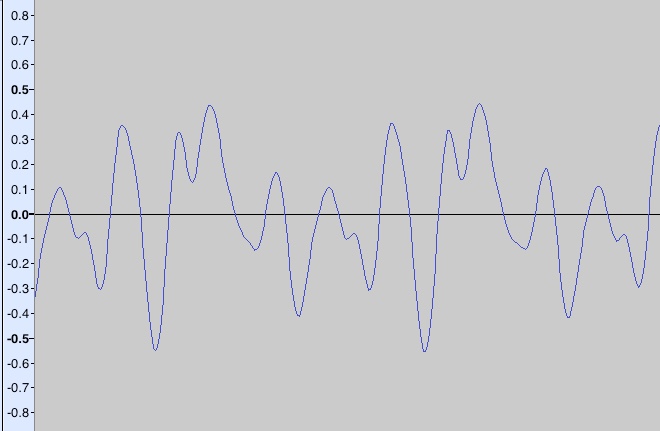
Trecho com 2 milisegundos de duração da forma de onda da parte tonal (ciclo) do som amostrado do trompete apresentado na figura anterior.
Desse modo, basta armazenar alguns ciclos deste trecho bem curto (ainda mais curto que o ataque) e repeti-los de modo quase periódico, modulados ao longo do tempo por uma envoltória dinâmica que representa os estágios mais comuns de uma nota musical. Estes são chamados de ADSR: Ataque, Decaimento (transição entre o ataque aperiódico e ciclo quase periódico), S (Steady state, ou modo estacionário, que é o período extenso onde a nota musical está soando) e R (Release, ou finalização da nota, quando esta é encerrada). Para regiões de notas próximas, o mesmo par de amostras (ataque e ciclo) podem ser usadas, bastando apenas modular ligeiramente a velocidade de leitura, correspondendo à variação de sua frequência (que corresponde à altura musical, ou pitch). Para regiões distantes, novos pares de amostras devem ser utilizados pois a diferença timbrística passa a ser perceptível (como ocorre quando aceleramos uma gravação de uma voz grave e esta soa não apenas de modo mais rápido, como uma voz fina, mas também como uma voz artificial, normalmente cômica por ser obviamente diferente de uma voz naturalmente mais fina). Para sons não tonais, como muitos sons percussivos (tambores, pratos, chocalhos) e efeitos sonoros (explosões, tiros, gritos), usa-se no processo da síntese wavetable apenas o ataque, que passa a ser bem maior e representa toda a extensão da amostra sonora.
Com o passar do tempo e o sucessivo avanço do desenvolvimento tecnológico, que permitiu a expansão do processamento e da memória computacional, a síntese wavetable, em nível comercial, substituiu completamente a síntese FM e a PM e até hoje é o método mais utilizado de síntese sonora digital. De fato, a síntese wavetable não é em si um processo de geração sonora mas um método de acesso e controle dinâmico de amostras de áudio digital em tempo real que se vale das propriedades do som de instrumentos tonais acima explicadas, onde curtas amostras digitais de pequenos trechos do som real são suficientes para “sintetizar” um som conhecido com bem menor esforço computacional e bem maior proximidade perceptual auditiva, muito acima daquela alcançada pelas sínteses sonoras anteriores, cujos sons podem ser reconstituídos e parametrizados em tempo real, pelos parâmetros de articulação fornecidos por um instrumento musical controlador, como um teclado MIDI (conforme apresentado na primeira parte desta série de artigos); fato este que parecia ser impossível de ser alcançado, mas que os inesperados avanços tecnológicos computacionais do final do século 20 DC acabaram viabilizando, para a surpresa e até quem sabe frustração de muitos pioneiros da computação musical.
Referências:
[] McNabb, Michael. “Dreamsong: The Composition” (PDF). Computer Music Journal. 5 (4). Retrieved February 24, 2015. http://www.mcnabb.com/music/pubs/CMJ_Vol5Num4.pdf
[] The History of the Electric Keyboard. By Gary Hill ; Updated September 15, 2017. https://ourpastimes.com/the-history-of-the-electric-keyboard-12310595.html
[] Sound synthesis of cymbals including thickness and shape variations. http://perso.ensta-paristech.fr/~touze/tapercymbals.html
[] Freesound https://freesound.org (acessado dia 19 de novembro de 2019)
Como citar este artigo:
José Fornari. “Avanços e caminhos da computação musical – parte 3”. Blogs de Ciência da Universidade Estadual de Campinas. ISSN 2526-6187. Data da publicação: 20 de novembro de 2019. Link: https://www.blogs.unicamp.br/musicologia/2019/11/20/35/