


Cabras™, porcos™, peixes™ e muito mais com marca registrada
Você pode não saber, mas o Brasil já é o segundo maior produtor de transgênicos do mundo, ficando atrás apenas do Estados Unidos. Até agora as alterações genéticas em escala comercial estiveram restritas apenas às plantas, com destaque para a soja e o milho. Mas não são apenas novos vegetais que os pesquisadores desejam colocar no mercado, animais geneticamente modificados aguardam aprovação para serem comercializados enquanto outros ainda passam por diversos testes. Confira cinco pesquisas que podem oferecer imensas vantagens para os consumidores, os produtores e até para o meio ambiente.
EnviropigTM
Com quase um bilhão de porcos no mundo, uma grande preocupação que se tem é o destino dos dejetos ricos em fósforo e nitrogênio. O EnviropigTM criado na Universidade de Guelph, no Canadá, foi concebido para ser um porco “eco-friendly”.
Grande parte do fósforo presente nos grãos e sementes que compõem a alimentação dos porcos estão na forma de fitato, um composto que eles não conseguem digerir e portanto são excretados. Para contornar esse problema, foi introduzido em seu genoma o gene da enzima fitase, o que torna possível aos porcos a digestão e absorção do fósforo desses alimentos. Dessa forma, o Enviropig excreta até 70% menos fósforo nas fezes.
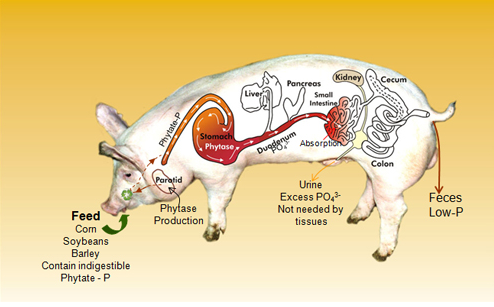
A pesquisa começou em 1995 e já recebeu patentes nos EUA e China, mas ainda não foi aprovado para consumo.
AquAdvantage®
O salmão AquAdvantage® deve ser o primeiro animal transgênico a ser aprovado para consumo pela Food and Drug Administration (FDA). Ele é igual ao salmão do atlântico em tamanho, aparência e gosto, exceto pelo fato de ter em seu genoma o gene de hormônio do crescimento do salmão do pacífico e DNA do peixe-carneiro americano.
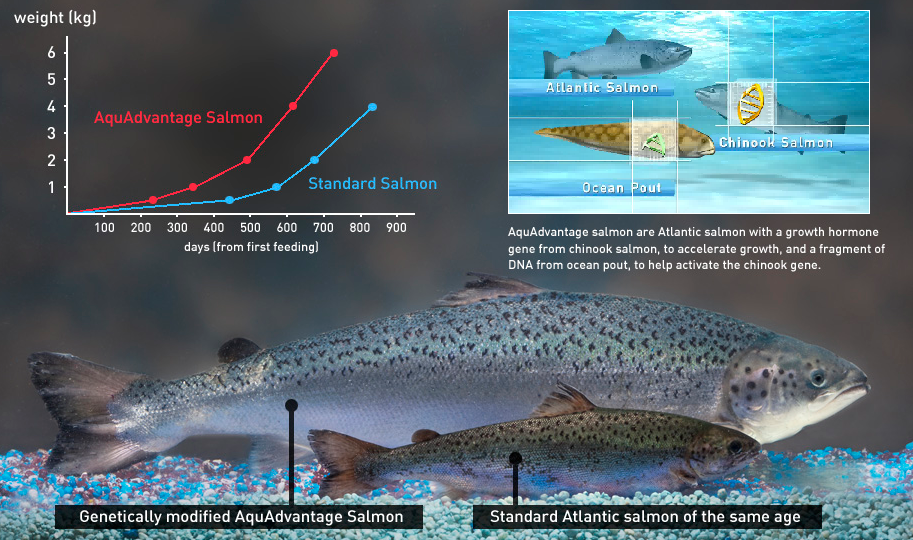
Essas alterações permitem que o salmão da empresa AquaBounty Technologies cresça duas vezes mais rápido que o salmão selvagem e consuma 25% menos alimento durante sua vida. Os peixes são estéreis e criados apenas em cativeiro. A pesquisa teve início em 1989 e, embora tenha-se concluído que o salmão não apresente riscos, ele ainda está em revisão pela FDA.
Porcos ricos em ômega-3
O consumo de alimentos ricos em omega-3 é recomendado por possuir poder anti-inflamatório e reduzir os riscos de doenças cardiovasculares. No entanto, nem todos os seres humanos têm acesso a esse tipo de alimento presente em grande quantidade nos peixes marinhos. Para oferecer uma carne alternativa ao peixe, rica em ômega-3, a solução até agora era alimentar os animais com linhaça, peixes e outros produtos marinhos, o que altera as características sensoriais da carne.

Para conseguir uma carne rica em ômega-3 sem alterar a alimentação dos animais, pesquisadores nos Estados Unidos criaram porcos com o gene fat-1 do verme Caenorhabditis elegans. O gene fat-1 permite que os porcos consigam converter ômega-6 em ômega-3. A pesquisa foi publicada na revista Nature Biotechnology mas ainda não há previsão de comercialização.
Cabras Transgênicas
A diarréia é responsável pela morte de mais de meio milhão de crianças todos os anos. Uma pesquisa que teve início em 1999 na Universidade da Califórnia – Davis (UCD), tem como objetivo obter um leite com poder anti-microbiano produzido com cabras que receberam o gene humano da enzima lisozima, proteína abundante no leite materno.

A pesquisa que começou nos Estados Unidos agora é feita em parceria com a Universidade do Ceará. O leite produzido pelas cabras transgênicas já mostrou efeitos terapêuticos em porcos, animais que têm um sistema digestivo parecido com o nosso. Os próximos passos serão os testes clínicos em humanos.
Porcos “editados”
Utilizando ferramentas de edição de genoma (Zinc Finger Nucleases – ZFNs e Transcription Activator-Like Effector Nucleases – TALENs), pesquisadores do Instituto Roslin, no Reino Unido, criaram porcos resistentes ao virus da febre suína Africana, capaz de matar os porcos europeus em menos de 24 horas.
Para tornar os porcos europeus resistentes foi necessário que uma única letra no genoma fosse alterada. A alteração foi feita com base no porco selvagem africano que é resistente ao virus, porém incapaz de cruzar com o porco europeu.
Os testes com os porcos devem começar esse ano e se tiverem sucesso serão submetidos à aprovação pela FDA.

Capazes de causar menor impacto ambiental, resistir a doenças e serem mais saudáveis, os animais geneticamente modificados podem ter um importante papel na alimentação da população mundial, que deve atingir 9 bilhões em 2050. Mesmo ainda enfrentando a oposição de ativistas, muitos pesquisadores acreditam que os animais modificados por ferramentas de edição de genoma devem ter sua aprovação acelerada pelas agências reguladoras. Caso isso aconteça, o Brasil não será apenas um dos maiores produtores de plantas™ geneticamente modificadas, mas também de animais™.
DNA como Código de Barras
 Desde o incrível advento do sequenciamento gênico lá pelos idos dos anos 70 o volume de dados obtidos das mais variadas combinações de nucleotídeos encontradas na natureza é estonteante. Fazendo um cálculo bem simples com só cinco nucleotídeos, temos 3125 combinações diferentes das letrinhas A,T,C e G!
Desde o incrível advento do sequenciamento gênico lá pelos idos dos anos 70 o volume de dados obtidos das mais variadas combinações de nucleotídeos encontradas na natureza é estonteante. Fazendo um cálculo bem simples com só cinco nucleotídeos, temos 3125 combinações diferentes das letrinhas A,T,C e G!
É lógico que hoje também conhecemos uma enorme quantidade de padrões dessas letrinhas que nos dizem: “Olha, aqui termina um gene!”, ou “É aqui que o ribossomo gruda!”, entre outras coisas. O ruim é que só à partir do DNA é bem mais trabalhoso e difícil dizer de qual criatura vieram aquelas informações encriptadas ali quando comparada à mera observação daquele ser vivo. E em alguns casos, mesmo que se conheça de onde vem o DNA, há a dúvida se ele veio mesmo de onde parece ter vindo: como se poderia ter certeza, por exemplo, se aquela bonita carteira de couro que te deram de presente não veio de uma espécie de jacaré em extinção em vez de um réptil criado em cativeiro!? A grande ideia é fazer o mesmo que você faz quando vai ao supermercado: em vez de escanear cada dobra da embalagem, abri-la, fazer uma fina análise do conteúdo, além de ter que sair por aí perguntado quanto custa, basta colocar aquela figurinha cheia de barras que existe em algum canto da embalagem num detector e pronto! Você passa a saber com rapidez do que se trata aquilo. No código genético tenta se fazer a mesma coisa.
A Vida Rotulada
A região do DNA (lócus) que deve ser usada para ser um “código de barras” (CB) tem que ao mesmo tempo ser conservada e variável, do mesmo modo que os CB’s são todos barrinhas pretas de mesmo tamanho, mas com comprimentos e espaçamentos variáveis. Essa região pode variar com os reinos dos seres vivos, mas no caso dos eucariotos, a região de 648 pares de bases do DNA mitocondrial que codifica a subunidade 1 da enzima citocromo mitocondrial C oxidase, é hoje amplamente usada como código de barras. O DNA mitocondrial é ideal para ser usado como CB uma vez que sua taxa de mutação nos seres vivos durante a evolução é muito alta, o que resulta em uma variação significativa das sequências entre as espécies.
Rotulando uma parte pelo todo é muito mais fácil para os biólogos associarem uma marca única de cada espécie às suas já elaboradas classificações do zoológico da vida, além de tornar muito mais fácil o controle, detecção e proteção de várias espécies de animais. Exitem grandes bancos de dados com um número crescente de DNA Barcodes (códigos de barras de DNA), um dos mais notórios é o projeto International Barcode of Life (Com site muito bonito aliás!) que já conta – pelo menos até agora pouco quando dei uma olhada – cerca de 1 milhão e 330 mil espécies no catálogo.
Código de Barras Literal
Aqui é o ponto em que a biologia sintética, ou pelo menos a engenharia genética, entra nisso tudo: como rotular os transgênicos? Bem, esse é um probleminha que foi bem discutido nos últimos anos que se passaram, principalmente porque as indústrias não queriam facilitar que sua tecnologia fosse copiada por outras companhias, enquanto governos e opinião pública queriam uma regulamentação que gerassem medidas que discriminassem um produto transgênico de um não-transgênico – um pouco por motivos ideológico-sociais, mas principalmente por motivos ecológicos: tornando a possibilidade de rastrear os culpados na hipótese de uma contaminação em certeza, haveria uma maior pressão para execução adequada das medidas de segurança impostas pela lei.
Foi aí então que criaram – ou melhor patentearam – uma padronização para códigos de barras bem interessante, que além de naturalmente tornar a identificação do transgênico muito mais fácil à partir de uma simples amostra de DNA, mantém a tecnologia em segredo e ainda conta com os mesmos processos utilizados em computador para correção de dados e compactação dos mesmos. Além dessa padronização que iremos explicar adiante, o próprio pessoal do Registro de Partes Padrão desenvolveu um Barcode para os Biobricks, que não é tão sofisticado, mas que corresponde à sua finalidade.
Escrevendo Com Quatro Letras
Para escrever textos com apenas quatro letras é muito simples se você sabe escrever
Imagem modificada retirada de http://tinyurl.com/3g46mnj
letras com números. Os computadores usam uma tabela que traduz o valores numéricos (ou melhor, bits) associados à um caractere do alfabeto alfanumérico: a famosa tabela ASCII. Para escrever letras no DNA então é muito mais fácil que no computador, principalmente porque ele utiliza o sistema binário de contagem, enquanto no DNA é possível usar o quaternário, com os 4 “números” possíveis: A, T, C e G, valendo 0, 1, 2, e 3 respectivamente (ver figura ao lado).
Com isso foi possível criar a seguinte (ver imagem abaixo) construção não-codificante de DNA que conta com informações relativas à por exemplo o nome da companhia, a espécie que foi modificada, ao ano em que o transgênico foi construído, e qual construção é aquela dentre todas as que a empresa possui. Ou seja, tudo aquilo que um código de barras em um transgênico precisa ter.

Imagem modificada retirada de http://tinyurl.com/3g46mnj
No caso da imagem acima, o sistema binário de contagem foi utilizado, em que 1 é a sequência TGT e 0 é TAC. Os números 1, 3 e 1 do nome da empresa, espécie e construção gênica seriam consultados em banco de dados, de modo a identificar produtor do transgênico.
Esse tema foi até um projeto do iGEM, realizado pelo time de Hong Kong em 2010, cuja a grande ideia foi criar um processo que literalmente criptografa dos dados inseridos em DNA através da ação de uma recombinase. Além disso desenvolveram um programinha que converte os dados de caracteres (char) à números quaternários, disso à ATCG e depois à uma versão compactada da sequência (Quanto maior e mais repetitivo o texto, melhor é a compactação, se o texto for pequeno e pouco repetitivo a compactação vai fazer o trabalho oposto); vale a pena dar uma olhadinha (nesse link aqui ó: http://2010.igem.org/Team:Hong_Kong-CUHK/Model).
Synbiobrasil no “alfabeto nucleotídico” é TTAGTGCTTCGCTCACTCCTTCGGTCACTGACTCATTGAGTCCTTCGA (grande né!?). 🙂
À Prova de Erros
Tanto em computadores como no sequenciamento genético erros podem acontecer, em que um 1 pode se tornar um 0 ou um A pode se tornar T (apesar de isso acontecer com muito mais frequência no DNA). Em ambos usa-se os mesmos métodos que podem identificar o erro, e se for pequeno, repará-lo, possibilitando a leitura correta da informação. Esses métodos chamam-se Checagem de Pares e Códigos Convolucionais, e utilizam bits… ops, quer dizer, utilizam números secundários usados para verificar a consistência dos dados. Têm-se então os números fonte (f), que são os que contém a informação a ser lida e os número de checagem de paridade (p), estes últimos têm valor 1 se um conjunto determinado de números fonte tiverem uma quantidade ímpar de 1s (“ums”) e zero se o contrário.
Na checagem de pares o negócio funciona com números de checagem verificando blocos de código. Por exemplo: os números fonte 1001 (f1 f2 f3 f4) são verificados por três números de checagem: p1, que verifica os três primeiros dígitos, p2 que verifica a paridade do primeiro, segundo e quarto dígitos, e p3 que verifica o primeiro, terceiro e quarto dígitos. Temos então o seguinte código de checagem de pares: 1001100 (números de checagem em itálico), pois:
- f1(1) + f2(0) + f3(0) = p1 (1), pois se tem “um 1”
- f1(1) + f2(0) + f4(1) = p2 (0), pois se tem “dois 1s”
- f1(1) + f3(0) + f4(1) = p3 (0), pois se tem “dois 1s”
Durante a leitura se não houver correlação entre os números de checagem e fonte, é possível dizer onde aconteceu o erro (caso o erro não seja generalizado). No exemplo foi utilizado um bloco de tamanho 4, mas ele pode ser maior, o que aumenta também o tamanho do código de checagem.
Utilizando Códigos de Convolução o processo é bem parecido, mas não ocorre em blocos, nele cada fn possui um pn que verifica os dois números fonte predecessores. Por exemplo, o número 1011 ficaria: 11011110 (f1 p1 f2 p2 f3 p3 f4 p4), pois:
- f1(1) = p1(1), pois se tem “um 1”
- f1(1) + f2(0) = p2(1), pois se tem “um 1”
- f2(0) + f3(1) = p3(1), pois se tem “um 1”
- f3(1) + f4(1) = p4(0), pois se tem “dois 1s”
Ensinando o computador a fazer os cálculos, utilizando esses dois métodos, e fazendo a conversão de zeros e uns para nucleotídeos (e vice-versa) é possível criar um sistema de leitura do sequenciamento genético do código de barras à prova de erros, preservando a informação original inserida na célula.
DNA “Zipado”
Assim como muita coisa na biologia sintética, os mesmos princípios da computação também podem ser aplicados na decodificação de informações inseridas em DNA. O mesmo algoritmo de compactação de arquivos usado na computação também pode ser usado para compactar as informações a serem inseridas em DNA, salvando espaço, tempo de leitura e dinheiro no bolso das empresas. É o amplamente conhecido Algoritmo de Codificação de Huffman (veja o link!), que se baseia no encurtamento de códigos bastante frequentes de um arquivo através de um algoritmo recursivo que constrói a “Árvore de Huffmam“, uma ramificação binária de nós de dados que contém informações relativas às frequências de caracteres. É preciso um pouco de conhecimento de programação para entender melhor como ele funciona; e isso foge um pouco do escopo desse post. Mas basta entender que você pode “zipar” as informações dentro do DNA!
Vale muito a pena conferir os links abaixo se você quiser saber mais sobre o assunto:
- http://ibol.org/resources/barcode-library/
- http://www.newscientist.com/article/dn3377-britain-may-force-dna-barcodes-for-gm-food.html
- http://partsregistry.org/Help:Barcodes
- http://2010.igem.org/Team:Hong_Kong-CUHK/Model
- http://worldwide.espacenet.com/publicationDetails/originalDocument?FT=D&date=20050323&DB=&locale=en_EP&CC=GB&NR=2376686B&KC=B
- http://en.wikipedia.org/wiki/DNA_barcoding
- http://pt.wikipedia.org/wiki/Codifica%C3%A7%C3%A3o_de_Huffman