


Sobre como calculei a CL50 usando o 'Statistica'

O calvário da biologia é a estatística.
Pra ser um bom biólogo, pra ser um bom cientista, você tem que saber estatística. E quanto mais, melhor. Só que… estatística é difícil! Bom, pelo menos pra mim.
Mesmo os conceitos mais básico, como ‘erro do tipo I e erro do tipo II’, ou de ‘normalidade’ sobre os quais eu até já escrevi, eu acho difíceis, e cada vez que necessito, tenho que pensar longamente sobre eles antes de ajustá-los as minhas observações.
E tem a matemática… sem ela, sua estatística vai ser muito limitada. Já vai ajudar, mas será insuficiente.
Mas, vocês sabem, eu sou um cara teimoso, e não me dou por vencido facilmente. Isso explica porquê eu passei a última semana, uma semana cheia de trabalho, gastando, todos os dias, várias horas, pra resolver um problema de estatística. Fiquei tão orgulhoso do resultado final que vou descrevê-lo aqui. Vai que alguém precisa?!
Bom, tudo começou quando eu estava revisando um artigo e descobri umas inconsistências nos resultados de uns testes de toxicidade. Os testes de toxicidade são bastante simples: a gente aplica a substância no indivíduo (em vários indivíduos, que não são pessoas mas mexilhões) e observa o efeito. Que, eventualmente, é a morte. Como aplicamos várias doses da substância, que nesse caso eram diferentes compostos de cloro, a gente pode calcular uma curva de dose-resposta, que, como o próprio nome diz, mostra o quanto o aumento do efeito em resposta ao aumento da dose. Certo?! Mais ou menos, porque a relação não é linear. Acontece que em doses pequenas da substância, o organismo não apresenta efeito algum, e em doses superiores àquela que matou todos os indivíduos expostos, o efeito se mantém (claro, não dá pra ter efeito maior do que todo mundo morto). Por isso é uma curva sigmoidal, aquela que se parece com um ‘S’. Resta a parte do meio dessa curva, que é o que nos interessa, porque nela a relação entre a dose e a resposta é linear. E por que isso é importante? Basicamente, porque o que é linear é mais fácil de calcular e de fazer previsões com base nesses cálculos.
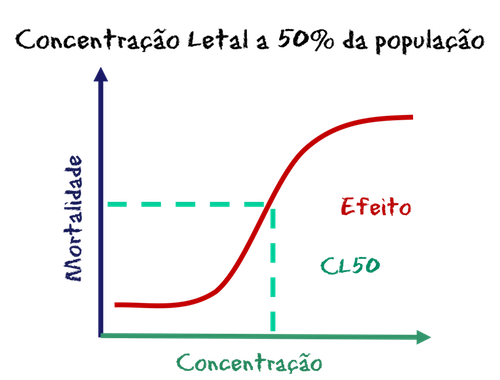
Mas o que a gente faz com a perninha inicial e a final do ‘S’, (ou, no jargão, a fase LAG e a fase LOG da curva sigmoidal)? Ignora? Deixa pra lá? Isso não é muito científico, então os cientistas resolveram apelar pra estatística e usaram uma ferramenta criada por um cidadão chamado Bliss, em 1934: a transformação em Probitos.
E o que vem a ser isso? Vamos lá, do começo. Os resultados de testes de toxicidade que medem mortalidade tem um agravante: medem mortalidade. Quer dizer, medem uma variável que é categórica e não contínua: vivo/morto.
Abre parênteses: esses são os dois únicos conceitos estatísticos que eu considero simples. Variáveis contínuas são aquelas que podem ser medidas em uma escala (como de 0 a 10, por exemplo, altura e peso) e categóricas são aquelas que dividem em classes (uma ou mais, como por exemplo sexo, cor dos olhos e também mortalidade. Fecha parênteses.
E com uma variável categórica da pra fazer bem menos coisas do que com uma contínua. Por exemplo, se a morte fosse uma variável contínua, como a pressão sanguínea, então eu poderia avaliar a efeitos intermediários. Quase vivo e quase morto, que são informações importantes. Será que aquele indivíduo que recebeu uma dose muito alta mas sobreviveu estava mais próximo de morrer ou estava vivinho da silva? Com uma variável discreta e binomial como a morte não dá pra eu responder isso. Pelo menos não sem estatística. E é ai que entra a transformação em probitos. Vamos imaginar que existe uma outra variável associada a morte, mas anterior, subjascente, a ela: a ‘quase morte’. A ‘quase morte’ é uma variável contínua e pode ser medida em uma escala que vai de ‘vivinho da silva’ até ‘mortinho da breca’, passando por todos os possíveis estágios intermediários. Qual é posição nessa escala de probabilidade, dadas as condições e os resultados do meu teste, um indivíduo que morreu na concentração 1? e na 2? e na 10?
É isso que a transformação de probitos me dá. A posição da minha variável discreta (qualitativa) na variável imaginária, subjascente, contínua (quantitativa). Ou pelo menos foi isso que eu conclui depois de uma semana debruçado sobre ela. A melhor explicação veio, como sempre, do livro eletrônico de estatística da Statsoft, que eu uso há muito tempo, e que continua sendo o único que me permite entender os conceitos. Talvez porque não venha com todos aqueles p, z, f etc.
O problema está resolvido e com a minha ‘variável contínua’ eu posso calcular a concentração de substância que afetaria 50% da população de animais expostos: A CE50 (que vira CL50 se o efeito em questão for letal). Vou deixar a discussão da validade da CL50 para outro momento, porque ela é longa, mas como é exigida para a publicação, não importa muito nesse momento.
Bom, o problema conceitual está resolvido, mas fazer o cálculo de probitos e estimar a CL50 não é nem um pouco trivial. A agência de proteção ambiental americana criou, muitos e muitos anos atrás, um software que calculava a CL50, mas que não evoluiu e continua em DOS. Gente… o DOS foi muito bom quando apareceu, mas atualmente… que descanse em paz! Qualquer erro de digitação tinha que repetir tudo. E usando MAC que nem eu… o transtorno é maior ainda. Além disso, o TKS não me deixava entrar todas as réplicas, técnicas ou biológicas, pedindo que eu agrupasse os dados para cada concentração. E abrir mão das minhas réplicas? Que deram tanto, mas tanto trabalho? De jeito nenhum!
Abre parênteses: O problema, posso dizer agora, não era só a falta de jeito de um software em DOS. Era que me faltava a compreensão real do que era a tal da transformação. Fecha parênteses.
Tinha de haver uma maneira de fazer isso em um pacote estatístico mais moderno, e eu transformei a tarefa de encontrar essa maneira na minha cruzada dessa semana. Não era possível que a única forma de calcular CL50 fosse com o famigerado TKS ou com o lamentável ‘probit’ (ambos em DOS). Escrevi para meus amigos que trabalham com ecotoxicologia e fazem testes de toxicidade para um monte de empresas, mas todos eles ainda usam o TKS. Não são pessoas doentes que nem eu, e estão plenamente satisfeitas com o DOS delas. Pra que mexer em time que está ganhando?
Sentei na cadeira, abri o meu emulador de Windows, abri o meu pacote preferido, o Statistica e me preparei pra batalha. Primeiro eu queria um botão ou uma expressão que me desse: ‘transformar a coluna 1 em probitos’. Mas não era tão simples assim. A probabilidade com base nessa ‘variável subjascente’ (a ‘quase morte’) só pode ser estimada com base na comparação entre número de vivos e número de mortos em cada concentração. Quando eu consegui achar a janela para a regressão por probitos, não conseguia entender que tantas variáveis eram aquelas que ele pedia. Enfim… como eu disse, foi uma semana de quebra-cabeça.
Mas enfim eu consegui. Calculei a CL50 dos experimentos no Statistica. Fiquei com tanto medo de não conseguir repetir o procedimento depois de dar certo a primeira vez, que tirei fotos da tela e montei um tutorial para mim mesmo (eu sei que daqui a meses ou anos quando tiver que fazer isso de novo, vou precisar rever toooooodos esses conceitos), que eu achei que poderia ser útil, pelo menos para meus amigos que ainda usam o TKS, e disponibilizo aqui: VQEB_tutorial_LC50_prob_stat_2011-Comments.
Diário de um biólogo – Sábado, 30/10/2010 – Último dia do ISMEE

Distribuímos formulários de avaliação do curso para os alunos, distribuímos os diplomas de participação e fomos para a festa de encerramento: um churrasco de peixe num quiosque na Praia do Forno. Depois da primeira caipirinha, Stegeman me abraçou e antes que ele dissesse alguma coisa eu mesmo falei “Missão Cumprida”! Ano que vem tem mais.
Diário de um biólogo – sexta, 29/10/2010 – Sétimo dia do ISMEE

Depois do almoço foi a vez do epidemiologista Antônio Pacheco falar. Uma vez, na mesa do bar, Antônio desmistificou um monte de opiniões que tínhamos baseadas em poucos argumentos e muito achismo sobre o quanto tubercuose, a AIDS e o câncer de pulmão entre fumantes eram realmente freqüentes. Se as suposições sem embasamento de dados são ruins para os leigos, imaginem para um cientista?! Por isso convidei a ele para falar dos sobre como a estatística precisa ser usada para resolver os desafios do dia-a-dia no laboratório.
A noite levei os professores para conhecer Búzios, o balneário de Brigitte Bardot, mas estávamos todos exaustos e a viagem foi mais cansativa. Infelizmente, Milton Moraes, Ricardo Zaluar e Aurélio Graça, três dos cinco palestrantes de sábado, cancelaram suas vindas e eu tive de reorganizar o dia seguinte como pude.
Terminei de ler… O andar do bêbado

“Alguns anos atrás, um homem ganhou na loteria nacional espanhola com um bilhete que terminava com o número 48. Orgulhoso por seu feito, ele revelou a teoria que o levou à fortuna. “Sonhei com o número 7 por 7 noites consecutivas”, disse, “e 7 vezes 7 é 48”
O primeiro parágrafo de O Andar do Bêbado de Leonard Mlodinow da um exemplo de quão grande é a nossa capacidade de abstrair a realidade em prol da nossa percepção da realidade.
Se você acha que uma coisa é, então ela será, não importa que ela não seja.
Entre os bons livros que tenho lido nos últimos tempos, esse é o que eu mais recomendaria, para um maior número de pessoas. Não importa se você é cientista, jogador e futebol, analista da bolsa de valores, advogado, jornalista, médico ou professor. Ao contrário do que prega Kardec, o acaso existe sim, e além de ser um fator determinante nas nossas vidas, é provavelmente o que menos pessoas conseguem entender.
Mas Leonard consegue te explicar sem nenhuma equação, em 90% do tempo sem nenhuma fórmula, ainda que use bastante números. Mas são números interessantíssimos e nada daquela chatice de dados e urnas (ainda que sim, esteja cheio de dados e urnas nos exemplos do livro).
Por exemplo, você sabia que a análise matemática das demissões de técnicos após o fracasso de seus times, em todos os grandes esportes, mostrou que, em média, elas não tiveram nenhum efeito no desempenho da equipe?
O maior desafio à compreensão do papel da aleatoriedade na vida é o fato de que, embora os princípios básicos dela surjam da lógica cotidiana, muitas das consequências que se seguem a esses princípios provam-se contraintuitivas. Que em qualquer série de eventos aleatórios, há uma grande probabilidade de que um acontecimento extraordinário (bom ou ruim) seja seguido, em virtude puramente do acaso, por um acontecimento mais corriqueiro.
Outro ponto importantíssimo levantado por Leonar é a importância da quantidade de informações. Enquanto a falta pode levar à concorrência entre diferentes interpretações, o excesso pode diferenciar o vencedor. Se os detalhes que recebemos em uma história se adequarem à imagem mental que temos de alguma coisa, então, quanto maior o número de detalhes, mais real ela parecerá (isso porque consideraremos que ela seja mais provável, muito embora o ato de acrescentarmos qualquer detalhe do qual não tenhamos certeza a torne menos provável)
O livro ainda faz pouco das pseudo-ciências que tentam ignorar o acaso. No caso da astrologia, o exemplo veio da Roma Antiga:
“Cícero, (…) Irritado com o fato de que, apesar de ilegal em Roma, a astrologia ainda continuasse viva e popular, (…)observou que [quando] Aníbal (…) trucidouum exército romano (…), abatendo mais de 60 mil de seus 80 mil soldados. “Todos os romanos que caíram em Canas teriam, por acaso, o mesmo horóscopo?”, perguntou? “Ainda assim, todos tiveram exatamente o mesmo fim”.
Mas acho que Leonard encontrará também bastante resistência, porque ele acaba com muitas das estatísticas dos esportes. Todos eles! Veja essa passagem e imagine como se aplicaria ao campeonato brasileiro:
“Se um dos times for [55%] melhor que o outro (…), ainda assim o time mais fraco vencerá uma melhor de 7 jogos cerca de 40% das vezes (…). E se o time superior for capaz de vencer seu oponente em 2 de cada 3 partidas, em média, o time inferior ainda vencerá uma melhor de 7 cerca de uma vez a cada 5 disputas. (…). Assim, as finais dos campeonatos esportivos podem ser divertidas e empolgantes, mas o fato de que um time leve o troféu não serve como indicação confiável de que realmente é o melhor time do campeonato.:
Que foi claramento o que aconteceu com o Flamengo no Brasileiro e com o Botafogo no Estadual. 😉
Mas a sacaneada mais bacana está nos médius:
“[em uma roleta] O trabalho do apostador é simples: adivinhar em qual compartimento cairá a bolinha. A existência de roletas é uma demonstração bastante boa de que não existem médiuns legítimos, pois emMonte CarIo, se apostarmos USD 1,00 em um compartimento e a bolinha cair ali, a casa nos pagará USD 35,00 (além do USD 1,00 que apostamos). Se os médiuns realmente existissem, nós os veríamos em lugares assim, rindo, dançando e descendo a rua com carrinhos de mão cheios de dinheiro, e não na internet, com nomes do tipo Zelda Que Tudo Sabe e Tudo Vê, oferecendo conselhos amorosos 24h, competindo com os outros 1,2 milhões de médiuns da internet.”
Mas falando mais sério, o livro é uma aula de matemática, história, estatística e ciências. Ele explica o ‘Triangulo de Pascal’, as ‘Provas de Bernoulli’, o ‘Teorema Áureo’, o surreal ‘Teorema dos pequenos números’, a ‘Distribuição Normal’ e o ‘Teorema do Limite Central’. E de forma que a gente entende.
Um fato que me chamou atenção, porque relacionei com a educação e com a avaliação de alunos, é ilustrado abaixo:
“Um diretor de empresa que tenha 60% de anos de sucesso, deve apresentar 60% de sucessos em um Periodo de 5 anos (que seriam aproximdamente 3)? Na verdade não! (vai ler o livro pra ver a explicação!) Na verdade é mais provável que 2/3 dos diretores tenham um resultado mais guiado pelo acaso do que pelas suas habilidade. Nas palavras do matemático Bernoulli: “Não deveríamos avaliar as ações humanas com base nos resultados:”. E sim nas suas habilidades
Um dos monstros da estatística praticamente desconhecido do público geral e louvado no livro é Bayes. Esse monge jamais publicou um único artigo científico e provavelmente realizou seu trabalho para satisfação própria. Bayes desenvolveu a probabilidade condicional em uma tentativa de resolver o problema: como podemos inferir a probabilidade subjacente a partir da observação?
Ou como traduziu Leonard: “Se um medicamento acabou de curar 45 dos 60 pacientes num estudo clínico, o que isso nos informa sobre a chance de que funcione no próximo paciente?
Novamente, não é uma questão fácil. Assim como eu que já fiz umas duas disciplinas de estatística Bayesiana garanto a vocês: Bayes é demais, mas é difícil demais.
Para Leonard, uma das pequenas contradições da vida é o fato de que, embora a medição sempre traga consigo a incerteza, esta raramente é discutida quando medições são citadas:
“Se uma policial de trânsito um tanto exigente diz ao juiz que, segundo o radar, você estava trafegando a 60km/h numa rua em que a velocidade máxima permitida é de 55km/h, você provavelmente será multado, ainda que as medições de radares com frequência apresentem variações de muitos quilômetros por hora.”
Ah… um capítulo a parte é o papel do acaso na avaliação de vinhos (também tem um sobre vodcas e outro sensacional sobre o efeito placebo da glicosamida), mas esses são tão bons que merecerão um post a parte
Finalmente ele aborda a questão com a qual inicia o livro: nossa habilidade para reconherce padrões, chamada de Heurística. Para Leonard, “Buscar padrões e atribuir-lhes significados faz parte da natureza Humana”.A heurística é muito útil, mas assim como nosso modo de processar informações ópticas pode levar às ilusões ópticas, a heurística também pode levar a erros sistemáticos. Ou erros de vieses.
“Todos nós utilizamos a heurística e padecemos de seus vieses. E o que é pior, temos o costume de avaliar equivocadamente o papel do acaso em nossas vidas, tomando decisões comprovadamente prejudiciais aos nossos interesses.”
Um desses exemplos é a ‘Falácia da Boa Fase’, experimentada por atletas de qualquer esporte (mas principalmente os mais assistidos); mas o mais chocante é o ‘Viés da confirmação’.
“Quando estamos diante de uma ilusão – ou em qualquer momento em que tenhamos uma nova ideia -, em vez de tentarmos provar que nossas ideias estão erradas, geralmente tentamos provar que estão corretas.”
Essa tendenciosidae representaria um grande impedimento à nossa tentativa de nos libertarmos da interpretação errônea da aleatoriedade. Como afirmou o filósofo Francis Bacon em 1620,
“a compreensão humana, após ter adotado uma opinião, coleciona quaisquer instâncias que a confirmem, e ainda que as instâncias contrárias possam ser muito mais numerosas e influentes, ela não as percebe, ou então as rejeita, de modo que sua opinião permaneça inabalada”.
Se o acaso é inevitável e a sorte é fundamental, então o diferencial pode não ser o talento (ainda que ele seja necessário), mas a persistencia.
“O primeiro Harry Potter, de J.K. Rowling, foi rejeitado por nove editores e o manuscrito de “A firma’, de John Grisham só atraiu o interesse de editores depois que uma cópia pirata que circulava em Hollywood lhe rendeu uma oferta de US$600 mil pelos direitos para a produção do filme.
Como observou Thomas Edison “muitos dos fracassos da vida ocorrem com pessoas que não perceberam o quão perto estavam do sucesso no momento em que desistiram!”
Não deixem de ler, absolutamente!
Sensibilidade e Especificidade

Em estatística, a gente diz que existem dois tipos de erro: ‘Erro do tipo I’ e ‘Erro do tipo II’, que são nomes terríveis, porque não ajudam em nada a gente a saber o que é um e o outro, demonstram uma total falta de criatividade dos estatísticos e tiram a curiosidade das pessoas para essa informação super importante.
Um nome muito melhor para o ‘Erro do tipo I’ é ‘falso alarme’ ou ‘falso positivo’. Esse tipo de erro acontece quando alguma coisa que você disse que era verdadeira, no final das contas se mostrou falsa. Eu sei que vocês não gostam de exemplos se estatísticos, aquelas coisas com ‘lançamentos de dados’ e ‘retirada de bolas de uma urna’, então vou tentar uma coisa mais na linha da fofoca.
O primeiro passo é fazer uma pergunta: “Será que ela(e) me ama?”
Ai você tem que recolher as evidências que podem te ajudar na resposta: o que ela(e) disse aqui, o que ela(e) fez ali, o que ela(e) falou lá. Junta, eventualmente, com algumas coisas que os outros dizem por ai, etc.
Depois você coloca tudo em um modelo e chega a uma conclusão: “Sim, ela(e) me ama”.
Um teste de hipótese até calcula a probabilidade da sua conclusão ser um falso alarme. (que nesse caso, significaria que tudo que ela(e) disse e fez foram na verdade obra do acaso e não do amor). E se a chance de ser um falso alarme for inferior a 5%, você toma a sua conclusão como certa (mesmo que na verdade a certeza seja de 95%).
Mas 95% é muito bom, não é?! É quase certo, não é?! Com 95% de certeza eu até vou pra debaixo da janela da pessoa fazer serenata de amor. Os 5% de chance de quebrar a cara estão lá, mas é melhor a gente se arrepender do que fez, do que daquilo que não fez, certo? Bem, pra fins didáticos, vamos dizer que sim.
Noventa e cinco por cento de chance de estar certo deve ser muito bom, porque se tornou um valor sagrado para os cientistas. Se a sua probabilidade p de estar errado é de 0,05 (que é igual a 95% de chance de estar certo) então sua hipótese será aceita, seus dados serão publicados, sua tese será aprovada. Caso contrário, se for 0,06; 0,1 ou qualquer outro valor maior que 0,05; então você é um pobre coitado.
Esse valor não depende dos dados. Esses sempre são o que são. Se você coletou bem, são bons dados (senão, você também é um pobre coitado). Também não é uma questão de interpretação dos dados. Diferentes interpretações podem levar a diferentes conclusões, mas a chance de estar certo ou errado é a mesma.
A questão está no quanto você se permite errar. Vejamos um outro exemplo: Se você souber que a chance de chover é 5%, você sai de casa com guarda-chuva? Bom, eu não. Só 5% de chance não é suficiente para me deixar carregando aquele trambolho pra lá e pra cá o dia todo. Mas para isso, e ai está a questão, você tem que aceitar que pode se molhar em 5% das vezes que sair de casa.
É verdade, nem todo mundo aceita. Tem gente que fica bravo com a chuva e amaldiçoa as gotas de água. Mas quem está na chuva deveria estar preparado pra se molhar, não é?!
Por outro lado, tem gente que sairia de casa sem o guarda-chuva mesmo se a chance de se molhar fosse 6, 7 ou até 10%. Ou até mais. Afinal, como disse Richard Gordon, ‘Cientificamente, embora seja deprimente, não passamos de sacos à prova d’água cheios de produtos químicos e carregados de eletricidade’. No nosso dia-a-dia podemos, e temos que, tomar decisões com percentuais menores do que 95% de certeza, mas os cientistas tem mesmo que manter esse alto padrão de qualidade.
Precisa porque o falso positivo é um problema duplo: você não só aceitou como verdadeira uma coisa que era falsa, como não descobriu a coisa verdadeira!
E é por isso que, em geral, não nos importamos muito com o ‘Erro do tipo II’, que é o falso negativo. Ele significa apenas que ‘perdemos uma boa oportunidade de descobrir a verdade’. Se ela(e) acha que você não a(o) ama, quando na verdade você ama, pode dar uma tremenda ‘dor de cabeça’, mas eventualmente novas evidências aparecerão para esclarecer a verdade. E essa é outra razão para nos importarmos menos com o falso negativo. A chance de cometer um erro do tipo II diminui muito com o acumulo de evidências a por isso, em geral, conseguimos evitar ele com o bom senso. Se você se baseia em apenas um bilhete que ela(e) te escreveu pra concluir ela(e) te ama, pode até ser o mais bonito poema já escrito, mas você nunca vai conseguir ter 95% de certeza que ela(e) te ama só com isso. Então, naturalmente, você busca mais argumentos para chegar a sua conclusão.
Erros do tipo I são erros de falta de especificidade: Um(a) te ama, o(a) outro(a) não, mas você não consegue ver a diferença. O erro do tipo II é um erro de falta de sensibilidade: ele(a) pode te amar, mas você não consegue saber com certeza. Se você corrige a sua falta de sensibilidade deveria, automaticamente, melhorar a sua falta de especificidade (ainda que não na mesma proporção). Na pratica, infelizmente, nem sempre funciona assim, porque a coerência, que é um pressuposto estatístico, não é uma qualidade humana inata.
Outra razão pode ser o ‘Erro do tipo III’ (descoberto depois dos dois primeiros) que é: ‘Você fez a pergunta errada!’
T.S.N. Totalmente Sem Noção

“Ele é mó TSN!”
Assim nos referíamos durante a faculdade aquelas pessoas que, mas do que nós (já que todos somos um pouco, ou eventualmente muito, TSN), tinham enorme falta de critério.
É verdade que o problema as vezes não é a falta de critério para avaliar uma informação, mas a falta de ferramentas para aplicar esse critério, mas isso é uma história para outro dia. Vou me ater agora a discussão da falta de critério mesmo.
O problema começa quando tentamos definir critério. Quando penso nele, me lembro da máxima que uma vez ouvi sobre o ‘bom senso’:
“Bom senso é a única coisa que todo mundo acha que já tem o suficiente e que não precisa de mais”.
Seria um mundo melhor se fosse verdade, não é mesmo?!
No livro “Cinco mentes para o futuro” de Howard Gardner, (presente da Soninha que eu terminei de ler no ano passado), ele sugere que precisamos de 5 ‘mentes’ para podermos viver bem no mundo contemporâneo:
“Com (…) elas, uma pessoa estará bem equipada para lidar com aquilo que se espera, bem como com o que não se pode prever. Sem elas, estará à mercê de forças que não consegue entender, muito menos controlar.”
Na descrição da primeira mente, a disciplinada, ele apresenta um mecanismo, ou uma atitude, que é aquela através da qual eu acredito que consigamos adquirir ‘critério’:
“A mente disciplinada é aquela que dominou pelo menos uma forma de pensar – um modo distintivo de cognição que caracteriza uma determinada disciplina acadêmica, um ofício ou uma prodissão. Muitas pesquisas confirmam que leva até 10 anos para se dominar uma disciplina. A mente disciplinada também sabe como trabalhar de forma permanente, ao longo do tempo, para melhorar a habilidade e o conhecimento (…). Sem pelo menos uma disciplina em sua bagagem, um indivíduo estará fadado a dançar conforme a música dos outros”
E sem ela, não terá chance de alcançar duas das outras ‘mentes’ importantes: a sintetizadora e a criativa (justamente porque lhe faltará… critério).
Vejamos um exemplo* da falta que o critério faz. Você sentou no buteco com os seus amigos que começaram a contar histórias.
1 – Milton conta impressionado que um amigo de um amigo seu, especialista em história da música, afirma que pode identificar se uma página de partitura é da autoria de Haydn ou Mozart. E que quando é submetido a um teste, em 10 tentativas, ele acerta todas.
2 – Barbosa conta que quando morou na Inglaterra, ouviu o zelador falar da Mrs. Surewater, que só tomava chá com leite, e que afirmava que podia identificar numa xícara que lhe fosse servida, se o leite ou o chá foram despejados primeiro. E que quando foi submetida ao teste, em 10 tentativas, ela acertou todas.
3 – Por fim Fernandinho contou que o seu amigo Richard, bêbado em fim de festa, afirmava ter a capacidade para predizer o resultado do lançamento de uma moeda honesta. E que quando foi submetido ao teste, em 10 tentativas, ele acertou todas.
Em qual dessas histórias você acredita? E em qual delas pode acreditar?
A explicação necessitaria de um outro post (ou de uma série de posts). Mas vou tentar resumir a duas respostas.
A estatística clássica diz que você pode confiar em todas, que não há razão para duvidar de nenhuma das 3. Porque ela é o que chamamos de ‘frequentista’ e trata esses eventos como ‘estatísticos’, ou, melhor ainda, ‘repetitivos’. Assim, basta confrontar os resultados com a hipótese de que eles acertaram por pura sorte (h0: p=0,5) e verificar que, com base nesses resultados, eles são capazes de fazer o que dizem (e assim rejeitamos h0). Mas você fica tranquilo com essa conclusão? Você apostaria dinheiro que seu amigo acertará na próxima moeda lançada? Ou que poderá enganar Mrs. Surewater na proxima xicará de chá que lhe oferecer?
Minha experiência prévia, que construiu o meu critério, me diz para apostar apenas na habilidade do amigo do Milton, especialista em história da música, em identificar corretamente a próxima partitura. Ainda que eu não saiba história da música a ponto avaliar se ele é realmente um bom especialista, capaz de acertar sempre, minha experiência com a minha disciplina, me diz que se você estudar bastante um assunto, é capaz de acertar (quase) sempre. Os meus parcos conhecimentos de teoria do Caos e mecânica de fluidos me dizem que é impossível que Mrs. Surewater saiba o que está fazendo, assim como os conhecimentos de estatística que o cotidiano nos dá já são suficientes para saber que o Richard não tem a capacidade de adivinhar a moeda, não importa o que diga o resultado do teste t.
O dilema aqui está relacionado com a diferença entre lógica indutiva e lógica dedutiva. Não podemos propor essa questão a estatística clássica, por isso a resposta dela não é válida. Como são problemas de lógica indutiva, como os são as hipóteses científicas e a maioria das nossas situações do cotidiano, não há como a conclusão ser obrigatoriamente verdadeira a partir das premissas, ainda que, verdadeiras. E isso já é problema demais para resolver. Não avaliar corretamente nossas premissas, as informações para chegar a uma decisão, é desperdiçar todo esse esforço.
Algumas decisões são simples: ‘sim’ ou ‘não’, (o que não quer dizer que elas sejam fáceis, dados o alcance e a magnitude das consequencias) e você não precisa de mecanismos sofisticados de decisão. Por isso (e mesmo quando as opções de escolha são mais complexas), vale muito mais a pena investir em informação para eliminar incertezas.
No texto anterior eu falei do mundo saturado de informação em que vivemos, e que a Internet facilita o acesso a ela, mas não nos ajuda a seleciona-la. Isso significa que sem você na interface, o Google tem muito pouca utilidade.
O Google não é uma referência! É preciso investir em você, e no seu critério.
Só que agora você está pensando: “Que saco!”, ou “Socorro!” ou simplesmente que tudo isso dá muito trabalho. E dá mesmo. Ainda conseguimos sobreviver sem ter de aplicar métodos estatísticos para as decisões do nosso dia-a-dia. Mas cada vez mais precisaremos avaliar informação para tomar decisões importantes. Aquelas que afetam a nós e as pessoas a nossa volta.
Por isso, exercite sempre o seu critério. Ou você pode virar o próximo TSN.
*Adaptado do exemplo no livro de “Introdução a estatística Bayesiana” do professor Paul Kinas (FURG).
Cuidado com o penteado

Pô, então eu vou me juntar ao coro dos que não gostaram do texto publicado na coluno Espiral do G1. O estudo de um indiano, publicado numa revista indiana, revela(?) a relação entre o sentido dos redemoinhos no couro cabeludo de homens e as suas preferências sexuais. Eu já escrevi sobre homsexualidade aqui e aqui e sei que é um tema acalorado. Mas é sempre um tema que desperta o interesse das pessoas, então sempre que há uma discussão científica sobre o assunto, vira notícia. O problema é que de ciência o artigo original tem muito pouca. Falta de embasamento teórico, seleção de observação, baixo número amostral, má aplicação de ferramentas estatísticas, conclusões tendenciosas… está tudo lá (vejam os comentários da matéria). Nossa… parecia até o exemplo que meu amigo usava nas aulas de estatística sobre como a eventual existência de correlação entre ‘dias de chuva x número de homens calvos’ em uma cidade não demonstra qualquer relação causal. A relação entre a preferência sexual, a orientação dos redemoinhos de cabelo e o uso de hemisférios do cérebro é tão fraca que eu arrisco a dizer que na verdade a orientação dos redemoinhos é um efeito da força de Coriolis (aquela relacionada com a rotação da Terra e que faz com que a água desça pelo ralo para a esquerda no hemisfério sul e para a direita no hemisfério norte). A impressão que dá é que o autor (do artigo) quis fazer uma brincadeira. E o autor da coluna quis fazer outra. Só que parece, pelos comentários, um monte de cientistas lêem a coluna e não acharam muita graça. Vai gente, foi brincadeira! Logo o Alysson que parece ser um cara preocupado com as mazelas do marketing científico a ponto de escrever um artigo sobre o tema no início do ano. Então acho que foi só uma brincadeira de gosto duvidoso mesmo. Tomara que ele publique logo outra coisa. Mas justamente quando o II EWCLiPo se propões a discutir o papel de cientistas e jornalistas na divulgação científica, não poderia deixar de comentar isso. Dá até pro Leandro usar na palestra dele.
Sei ou não sei? Eis a questão!
O tema do Roda de Ciência desse mês é ‘A importância da comunicação da incerteza para o público leigo’.

Eu não tenho certeza, mas foi com o prof. Paul Kinas, e não com Heisenberg, que eu passei a perceber a incerteza do mundo. Ele era um mago da estatística Bayesiana que ensinava estatística como filosofia de vida. Filosofia que eu adotei.
Marcelo Gleiser começa o livro ‘Dança do Universo‘ falando da importância da dualidade para o ser humano: Dia e Noite, Claro e Escuro, Quente e Frio, Certo e Errado! O meu professor de estatística dizia que o problema é que nós não fomos educados a conviver com a incerteza. Durante toda nossa educação formal, fomos obrigados à escolher entre o ‘certo’ e o ‘errado’. Não nos ensinaram que as coisas, muitas delas, eram (e sempre serão) ‘incertas’. Aprendemos a fazer aproximações, aprendemos a escolher entre o ‘certo’ e o ‘errado’. Mas não aprendemos que entre os dois existe o ‘incerto’. Aliás, é muito pior, aprendemos a ignorar o incerto, ou tortura-lo até que se torne ‘certo’ ou ‘errado’. O resultado é desastroso: a grande incapacidade da maioria das pessoas de entender a ciência.
O Kinas dizia que deveríamos poder, na escola, escolher o certo apontando nosso grau de certeza relacionado com a escolha: “Acho que está certo, mas tenho com 70% de certeza!” Não seria lindo poder dar uma resposta dessas no vestibular?
Bom, ele nos deu uma prova assim. Lembro até hoje de algumas das perguntas:
“Qual cidade tem maior área urbana, Rio de Janeiro ou Buenos Aires?” Bairrista, respondi ‘Rio’ sem titubear. 95% de certeza! Mas como a geografia não se dobra a emoção, errei e perdi muitos pontos. Porém, mais pontos perdia quem dissesse que ‘sim’ ou que ‘não’ com 50% de certeza (que reflete não só a ignorância, mas o descaso e o descompromisso com a questão). Isso trás outra questão: a importância de escolher. O fato de existir incerteza não nos exime de ter de tomar decisões frente à ela.
Os psicólogos vão dizer que sempre fazemos escolhas, pois mesmo quem não escolhe, está fazendo uma escolha. E está mesmo. Só que as pessoas acham que têm de estar seguras do ‘certo’ pra escolher, quando o que nos diferencia do todo são justamente nossas escolhas frente ao incerto. Já escrevi aqui que acreditar no óbvio é fácil. Tomar decisões quando se tem todas as informações também é. Já quando a gente não sabe…
Bem, quando a gente não sabe, pode sempre recorrer ao ‘Cálculo de utilidades’ e as muitas outras ferramentas de ‘Tomada de decisão’ e ‘Análise de risco’, que a estatística tem a nos oferecer. E que, diga-se de passagem, deveriam ser matéria obrigatória na escola, porque podem ajudar muito a escolher a melhor opção frente a incerteza. Da mesma forma que companhias de seguro e cassinos fazem (e ganham rios de dinheiro com isso).
Mas enquanto isso não entra no currículo, poderíamos pelo menos parar de perguntar aos nossos alunos ‘se’ eles sabem, e começar a perguntar ‘o que’ ou ‘o quanto’ eles sabem.
Por favor, comentários aqui!
'Outliers' e 'Outsiders'

Toda aquela coisa para explicar a normalidade, foi com o intuito de relaciona-la com a previsibilidade. Em muitas situações não temos previsibilidade e quando isso acontece, quase sempre, é por causa da falta de normalidade dos dados. Terminei o texto sobre alando de como fazer para lidar com os anormais. Anormais, no sentido estatístico, são os assimétricos.
A questão curiosa é que, quem define a normalidade de uma dado, não é o dado em si, mas a distribuição a qual ele pertence. Na festa dos joqueis, os jogadores de basquete são anormais, no festa dos jogadores de voley, nem tanto.
Dependendo de com quem ele ande, um determinado dado, será sempre normal.
Se você é muito crítico, como eu sou, a curva normal que descreve o mundo é relativamente estreita, concentrada. Ou, estaticamente falando, leptocúrtica. Essa curva forma um sino muuuuito alto e muuuuito estreito. Na verdade mais parecido com um gramofone que com um sino. Conheço muita gente na média, e considero um monte de gente fora dela também. Eu juro que estou tentando mudar isso. Tornar a minha curva mais mesocúrtica (um sino normal) ou até mesmo um pouco platicúrtica (um sino achatado, quase como uma ondulação, onde tem quase tanta gente nas extremidades quanto na média). Que nem uma campainha de mesa.

Cada um de nós tem sua descrição normal do mundo, e tenta encaixar tudo que encontra nessa descrição. Para que o mundo se torne previsível e confortável. E é possível encaixar alguma coisa na distribuição normal? É sim.
Um ponto que está fora da distribuição é chamado de ‘outlier‘. Fora da linha. Tenho uma amiga que gosta de pessoas (mais do que de dados), e nesses casos ela usa o termo de Outsiders: os excluídos.
Estatisticamente, existe um conjunto de artifícios matemáticos para lidar com os outliers e encaixa-los na distribuição normal. Esses artifícios são chamados, convenientemente, de transformações. O logaritmo, por exemplo, é uma função que diminui a discrepância entre duas coisas diferentes. Por isso, é possível utilizar o log em um determinado dado para que ele se encaixe na sua distribuição.
Parece doidera, não é? Transformar um dado apenas para que ele se encaixe no que você conhece e possa entende-lo?
Mas é porque não? Você pode calcular o log de um número e o número de volta, quantas vezes quiser. O log e o número permanecem sempre o mesmo. E por que você faria isso? Porque pode ser mais fácil entender a relação entre o log de dois números do que entre os dois números em si. Principalmente, se os logs se comportam de forma… normal.
A vida reserva surpresas e muitas coisas novas também. Felizmente! Nossa primeira tendência, como falei aqui, é tentar encaixar algo novo nas categorias das “coisas que conhecemos”. Quando elas não se encaixam, tentamos dar uma ‘transformada’ nelas. Uma outra amiga chamaria isso de ‘enfeitar’.
Mas o que o cientista dentro de todos nós deveria aprender a fazer? Procurar a ferramenta mais adequada para lidar cada nova coisa nova. Criar essa ferramenta, se for necessário. Existe uma distribuição normal, simétrica. Mas existem muito mais distribuições assimétricas. E apesar das formas de lidar com elas sejam menos eficientes do que as paramétricas, você não precisa transformar nada. Nem ninguém.
Isso é trabalhoso, é cansativo. Mas como tantas coisas trabalhosas e cansativas, tem grandes recompensas. Então o problema não é esse, o problema é quando isso é impossível.
PS: A idéia e alguns instrumentos para a discussão da normalidade vieram de uma das muitas conversas com minha querida amiga e bióloga Cris.
Quantas vezes o Vasco ainda vai perder do Botafogo?

Uma das coisas que me irrita nas transmissões de futebol são as estatísticas. Só perdem pro Galvão Bueno.
“Desde 1932, Vasco e Botafogo se enfrentaram 763 vezes, com 22% de vitórias para um, 44% de empates e 34% de vitórias para o outro”. Não, não sei se esses são os números corretos. Está tarde e estou com preguiça de procurar. Mas não importa.
E não importa porque, nesse caso, essa estatística não se aplica!
A probabilidade pode ser calculada para eventos repetitivos. Um dado sendo jogado muitas vezes permite apenas um determinado número de possibilidades, eventos, que se repetem exaustivamente. Esse é um evento repetititvo, onde todo o universo de possibilidades é conhecido.
Mas mutios outros eventos, a maioria dos eventos da vida real, não são repetitivos e as probabilidades associadas a eles não dependem de quantas vezes você repete, mas sim da aquisição de novas informações.
O fato de chover todo o dia 15 de junho nos últimos 23 anos, não define nenhuma probabilidade de que va chover hoje. As massas de ar, pressão atmosférica, temperatura, umidade… isso sim, pode te ajudar a decidir se vai sair com guarda chuva ou não
“O Botafogo não perde para o Vasco há mais de 10 jogos”
Essa parece uma estatística um pouco melhor. Porque os times devem ser os mesmos, assim como os técnicos, táticas de jogo… Mesmo assim, basta um jogador torcer o pé, outro comer feijão demais que… acaba toda a ‘repetibilidade’ do evento.
As estatísticas furadas são mais um motivo para você desligar o som da TV quando está assistindo futebol. Elas não ajudam a prever… NADA! E com isso só posso torcer para que a maré de sorte do Botafogo termine logo!




